VictoriaMetrics is a fast, cost-effective, and scalable solution for monitoring and managing time series data. It delivers high performance and reliability, making it an ideal choice for businesses of all sizes.
- Case studies: Grammarly, Roblox, Wix, Spotify,… .
- Available: Binary releases , Docker images on Docker Hub and Quay , Source code .
- Deployment types: Single-node version and Cluster version under Apache License 2.0 .
- Getting started: Read key concepts and follow the quick start guide .
- Community: Slack (join via Slack Inviter ), X (Twitter) , YouTube . See full list here .
- Changelog: Project evolves fast - check the CHANGELOG , and How to upgrade .
- Enterprise support: Contact us for commercial support with additional enterprise features .
- Enterprise releases: Enterprise and long-term support releases (LTS) are publicly available and can be evaluated for free using a free trial license .
- Security: we achieved security certifications for Database Software Development and Software-Based Monitoring Services.
There is also user-friendly database for logs - VictoriaLogs .
Prominent features #
- Supports all the features of the single-node version .
- Performance and capacity scale horizontally. See these docs for details .
- Supports multiple independent namespaces for time series data (aka multi-tenancy). See these docs for details .
- Supports replication. See these docs for details .
It is recommended to use the single-node version for ingestion rates lower than a million data points per second. The single-node version scales perfectly with the number of CPU cores, RAM and available storage space and can be set up in High Availability mode. The single-node version is easier to configure and operate compared to the cluster version, so think twice before choosing the cluster version. See this question for more details.
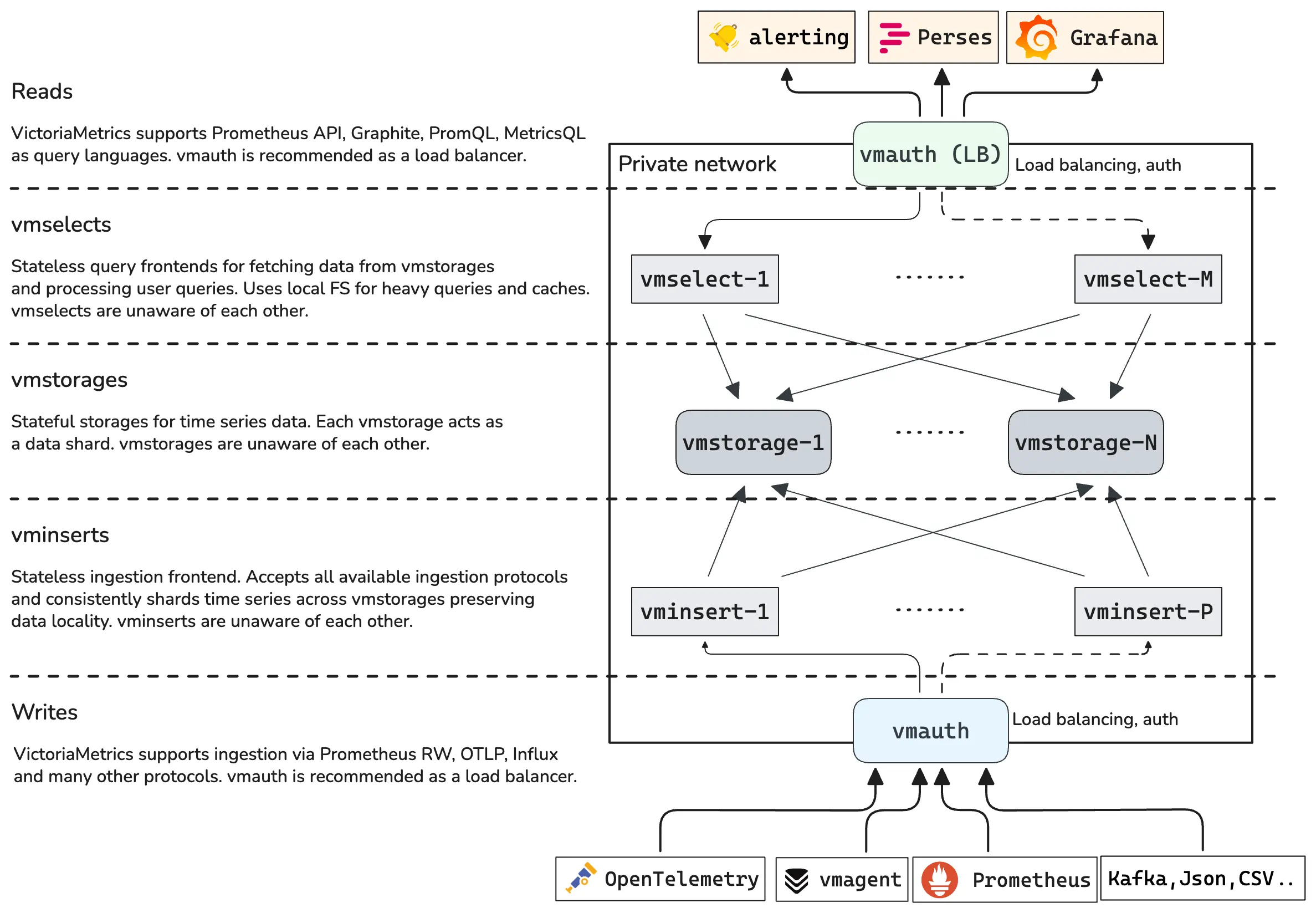
Architecture overview #
VictoriaMetrics cluster consists of the following services:
vmstorage- stores the raw data and returns the queried data on the given time range for the given label filtersvminsert- accepts the ingested data and spreads it amongvmstoragenodes according to consistent hashing over metric name and all its labelsvmselect- performs incoming queries by fetching the needed data from all the configuredvmstoragenodes
Each service may scale independently and may run on the most suitable hardware.
vmstorage nodes don’t know about each other, don’t communicate with each other and don’t share any data.
This is a shared nothing architecture
.
It increases cluster availability, and simplifies cluster maintenance as well as cluster scaling.
vmui #
VictoriaMetrics cluster version provides UI for query troubleshooting and exploration. The UI is available at
http://<vmselect>:8481/select/<accountID>/vmui/ in each vmselect service.
The UI allows exploring query results via graphs and tables. See more details about
vmui
.
Multitenancy #
VictoriaMetrics cluster supports multiple isolated tenants (aka namespaces).
Tenants are identified by accountID or accountID:projectID inside request URLs or HTTP headers
Available from v1.143.0
for writes and reads. See
these docs
for details.
Some facts about tenants in VictoriaMetrics:
Each
accountIDandprojectIDis identified by an arbitrary 32-bit integer in the range[0 .. 2^32). IfprojectIDis missing, then it is automatically assigned to0. It is expected that other information about tenants such as auth tokens, tenant names, limits, accounting, etc. is stored in a separate relational database. This database must be managed by a separate service sitting in front of VictoriaMetrics cluster such as vmauth or vmgateway . Contact us if you need assistance with such service.Tenants are automatically created when the first data point is written into the given tenant.
Data for all the tenants is evenly spread among available
vmstoragenodes. This guarantees even load amongvmstoragenodes when different tenants have different amounts of data and different query load.The database performance and resource usage do not depend on the number of tenants. It depends mostly on the total number of active time series in all the tenants.
The list of registered tenants can be obtained via
http://<vmselect>:8481/admin/tenantsurl. See these docs .VictoriaMetrics exposes various per-tenant statistics via metrics - see these docs .
See also multitenancy via headers and via labels .
Multitenancy via headers #
By default, VictoriaMetrics allows specifying accountID and projectID only in the request URL.
Set --enableMultitenancyViaHeaders
Available from v1.143.0
command-line flag to support
specifying accountID and projectID via HTTP headers AccountID and ProjectID respectively.
This flag needs to be specified separately for vminserts and vmselects.
When --enableMultitenancyViaHeaders is enabled,
URL format
can be simplified to the following:
http://<vminsert>:8480/insert/<suffix>for writeshttp://<vmselect>:8481/select/prometheus/<suffix>for reads
For example, the following query will only select metric up from accountID=2 and projectID=3:
curl 'https://<vmselect>:8481/select/prometheus/api/v1/query' \
-d 'query=up' \
--header "AccountID: 2" \
--header "ProjectID: 3"
The following example will ingest metric up{instance="foo"} to accountID=2 and projectID=0:
curl --header "AccountID: 2" -d 'up{instance="foo"} 123' -X POST https://<vminsert>:8480/insert/prometheus/api/v1/import/prometheus
When simplified path /(insert|select)/<suffix> is used and headers AccountID, ProjectID are missing, then IDs are set to 0:0 as default.
If tenant IDs are specified in URL, then headers are ignored.
The AccountID header can be set to multitenant string: AccountID: multitenant. See more in
multitenancy via labels
.
Multitenancy via labels #
Multitenancy via labels allows specifying
tenants
as labels vm_account_id and vm_project_id during
ingestion or querying. This feature allows
ingesting workload with mixed tenants
and
querying
data from multiple tenants
via the same URL.
Multitenant writes #
vminsert can accept data from multiple
tenants
via special multitenant endpoints:
http://vminsert:8480/insert/multitenant/<suffix>http://vminsert:8480/insert/<suffix>and HTTP headerAccountID: multitenant. See how to enable headers here . where<suffix>can be replaced with any supported suffix for data ingestion from this list . TheaccountIDandprojectIDare obtained from optionalvm_account_idandvm_project_idlabels of the incoming samples. Ifvm_account_idorvm_project_idlabels are missing or invalid, then the correspondingaccountIDandprojectIDare set to 0. These labels are automatically removed from samples before forwarding them tovmstorage. For example, if the following samples are written intohttp://vminsert:8480/insert/multitenant/prometheus/api/v1/write:
http_requests_total{path="/foo",vm_account_id="42"} 12
http_requests_total{path="/bar",vm_account_id="7",vm_project_id="9"} 34
Then the http_requests_total{path="/foo"} 12 would be stored in the tenant accountID=42, projectID=0,
while the http_requests_total{path="/bar"} 34 would be stored in the tenant accountID=7, projectID=9.
The vm_account_id and vm_project_id labels are extracted after applying the
relabeling
set via -relabelConfig command-line flag, so these labels can be set at this stage.
The vm_account_id and vm_project_id labels are also taken into account when ingesting data via non-http-based protocols
such as
Graphite
,
InfluxDB line protocol via TCP and UDP
and
OpenTSDB telnet put protocol
.
Multitenant reads #
For better performance prefer specifying tenants in read URL .
vmselect can execute
Available from v1.104.0
queries over multiple
tenants
via special multitenant endpoints:
http://vmselect:8481/select/multitenant/<suffix>http://vmselect:8481/select/<suffix>and HTTP headerAccountID: multitenant. See how to enable headers here .
Currently supported endpoints for <suffix> are:
/prometheus/api/v1/query/prometheus/api/v1/query_range/prometheus/api/v1/series/prometheus/api/v1/labels/prometheus/api/v1/label/<label_name>/values/prometheus/api/v1/status/active_queries/prometheus/api/v1/status/top_queries/prometheus/api/v1/status/tsdb/prometheus/api/v1/export/prometheus/api/v1/export/csv/prometheus/api/v1/metadata/vmui
It is allowed to explicitly specify tenant IDs via vm_account_id and vm_project_id labels in the query.
For example, the following query fetches metric up for the tenants accountID=42 and accountID=7, projectID=9:
up{vm_account_id="7", vm_project_id="9" or vm_account_id="42"}
vm_account_id and vm_project_id labels support all operators for label matching. For example:
up{vm_account_id!="42"} # selects all the time series except those belonging to accountID=42
up{vm_account_id=~"4.*"} # selects all the time series belonging to accountIDs starting with 4
Alternatively, it is possible to use
extra_filters[] and extra_label
query args to apply additional filters for the query:
curl 'http://vmselect:8481/select/multitenant/prometheus/api/v1/query' \
-d 'query=up' \
-d 'extra_filters[]={vm_account_id="7",vm_project_id="9"}' \
-d 'extra_filters[]={vm_account_id="42"}'
The precedence for applying filters for tenants follows this order:
- Filter tenants by
extra_label,extra_filtersandextra_filters[]filters. These filters have the highest priority and are applied first when provided through the query arguments. Filters useORlogic - a tenant is selected if it matches any of the filters. - Filter tenants from labels selectors defined at metricsQL query expression.
Security considerations
It is recommended restricting access to multitenant endpoints only to trusted sources,
since untrusted source may break per-tenant data by writing unwanted samples or get access to data of arbitrary tenants.
See also
vmauth security doc
.
Binaries #
Compiled binaries for the cluster version are available in the assets section of the releases page
.
Also see archives containing the word cluster.
Docker images for the cluster version are available here:
vminsert- Docker Hub and Quayvmselect- Docker Hub and Quayvmstorage- Docker Hub and Quay
Building from sources #
The source code for the cluster version is available in the cluster branch .
Production builds #
There is no need to install Go on a host system since binaries are built inside the official docker container for Go . This allows reproducible builds. So install docker and run the following command:
make vminsert-prod vmselect-prod vmstorage-prod
Production binaries are built into statically linked binaries. They are put into the bin folder with -prod suffixes:
$ make vminsert-prod vmselect-prod vmstorage-prod
$ ls -1 bin
vminsert-prod
vmselect-prod
vmstorage-prod
Development Builds #
- Install go .
- Run
makefrom the repository root . It should buildvmstorage,vmselectandvminsertbinaries and put them into thebinfolder.
Building docker images #
Run make package. It will build the following docker images locally:
victoriametrics/vminsert:<PKG_TAG>victoriametrics/vmselect:<PKG_TAG>victoriametrics/vmstorage:<PKG_TAG>
<PKG_TAG> is auto-generated image tag, which depends on source code in the repository
.
The <PKG_TAG> may be manually set via PKG_TAG=foobar make package.
By default, images are built on top of alpine
image in order to improve debuggability.
It is possible to build an image on top of any other base image by setting it via <ROOT_IMAGE> environment variable.
For example, the following command builds images on top of scratch
image:
ROOT_IMAGE=scratch make package
High availability #
The database is considered highly available if it continues accepting new data and processing incoming queries when some of its components are temporarily unavailable. VictoriaMetrics cluster is highly available according to this definition - see cluster availability docs .
It is recommended to run all the components for a single cluster in the same subnetwork with high bandwidth, low latency and low error rates. This improves cluster performance and availability. It isn’t recommended spreading components for a single cluster across multiple availability zones, since cross-AZ network usually has lower bandwidth, higher latency and higher error rates comparing the network inside a single AZ.
If you need multi-AZ setup, then it is recommended running independent clusters in each AZ and setting up
vmagent
in front of these clusters, so it could replicate incoming data
into all the cluster - see
these docs
for details.
Then an additional vmselect nodes can be configured for reading the data from multiple clusters according to
these docs
.
See victoria-metrics-distributed chart for an example.
Cluster setup #
A minimal cluster must contain the following nodes:
- a single
vmstoragenode with-retentionPeriodand-storageDataPathflags - a single
vminsertnode with-storageNode=<vmstorage_host> - a single
vmselectnode with-storageNode=<vmstorage_host>
Enterprise version of VictoriaMetrics
supports automatic discovering and updating of vmstorage nodes.
See
these docs
for details.
It is recommended to run at least two nodes for each service for high availability purposes. In this case the cluster continues working when a single node is temporarily unavailable and the remaining nodes can handle the increased workload. The node may be temporarily unavailable when the underlying hardware breaks, during software upgrades, migration or other maintenance tasks.
It is preferred to run many small vmstorage nodes over a few big vmstorage nodes, since this reduces the workload increase on the remaining vmstorage nodes when some of vmstorage nodes become temporarily unavailable.
An http load balancer such as
vmauth
or nginx must be put in front of vminsert and vmselect nodes.
It must contain the following routing configs according to
the url format
:
- requests starting with
/insertmust be routed to port8480onvminsertnodes. - requests starting with
/selectmust be routed to port8481onvmselectnodes.
Ports may be altered by setting -httpListenAddr on the corresponding nodes.
It is recommended setting up monitoring for the cluster.
The following tools can simplify cluster setup:
- An example docker-compose config for VictoriaMetrics cluster
- Helm charts for VictoriaMetrics
- Kubernetes operator for VictoriaMetrics
It is possible manually setting up a toy cluster on a single host. In this case every cluster component - vminsert, vmselect and vmstorage - must have distinct values for -httpListenAddr command-line flag. This flag specifies http address for accepting http requests for
monitoring
and
profiling
. vmstorage node must have distinct values for the following additional command-line flags in order to prevent resource usage clash:
-storageDataPath- everyvmstoragenode must have a dedicated data storage.-vminsertAddr- everyvmstoragenode must listen for a distinct tcp address for accepting data fromvminsertnodes.-vmselectAddr- everyvmstoragenode must listen for a distinct tcp address for accepting requests fromvmselectnodes.
Cluster availability #
VictoriaMetrics cluster architecture prioritizes availability over data consistency. This means that the cluster remains available for data ingestion and data querying if some of its components are temporarily unavailable.
VictoriaMetrics cluster remains available if the following conditions are met:
HTTP load balancer must stop routing requests to unavailable
vminsertandvmselectnodes ( vmauth stops routing requests to unavailable nodes).At least a single
vminsertnode must remain available in the cluster for processing data ingestion workload. The remaining activevminsertnodes must have enough compute capacity (CPU, RAM, network bandwidth) for handling the current data ingestion workload. If the remaining activevminsertnodes have no enough resources for processing the data ingestion workload, then arbitrary delays may occur during data ingestion. See capacity planning and cluster resizing docs for more details.At least a single
vmselectnode must remain available in the cluster for processing query workload. The remaining activevmselectnodes must have enough compute capacity (CPU, RAM, network bandwidth, disk IO) for handling the current query workload. If the remaining activevmselectnodes have no enough resources for processing query workload, then arbitrary failures and delays may occur during query processing. See capacity planning and cluster resizing docs for more details.At least a single
vmstoragenode must remain available in the cluster for accepting newly ingested data and for processing incoming queries. The remaining activevmstoragenodes must have enough compute capacity (CPU, RAM, network bandwidth, disk IO, free disk space) for handling the current workload. If the remaining activevmstoragenodes have no enough resources for processing query workload, then arbitrary failures and delay may occur during data ingestion and query processing. See capacity planning and cluster resizing docs for more details.
The cluster works in the following way when some of vmstorage nodes are unavailable:
vminsertre-routes newly ingested data from unavailablevmstoragenodes to remaining healthyvmstoragenodes. This guarantees that the newly ingested data is properly saved if the healthyvmstoragenodes have enough CPU, RAM, disk IO and network bandwidth for processing the increased data ingestion workload.vminsertspreads evenly the additional data among the healthyvmstoragenodes in order to spread evenly the increased load on these nodes. During re-routing, healthyvmstoragenodes will experience higher resource usage and increase in number of active time series .vmselectcontinues serving queries if at least a singlevmstoragenodes is available. It marks responses as partial for queries served from the remaining healthyvmstoragenodes, since such responses may miss historical data stored on the temporarily unavailablevmstoragenodes. Every partial JSON response contains"isPartial": trueoption. If you prefer consistency over availability, then runvmselectnodes with-search.denyPartialResponsecommand-line flag. In this casevmselectreturns an error if at least a singlevmstoragenode is unavailable. Another option is to passdeny_partial_response=1query arg to requests tovmselectnodes.vmselectalso accepts-replicationFactor=Ncommand-line flag. This flag instructsvmselectto return full response if less than-replicationFactorvmstorage nodes are unavailable during querying, since it assumes that the remainingvmstoragenodes contain the full data. See these docs for details.It is also possible to configure independent replication factor per distinct
vmstoragegroups - see these docs .
vmselect doesn’t serve partial responses for API handlers returning
raw datapoints
,
since users usually expect this data is always complete. The following handlers return raw samples:
/api/v1/export*endpoints/api/v1/querywhen thequerycontains series selector ending with some duration in square brackets. For example,/api/v1/query?query=up[1h]&time=2024-01-02T03:00:00Z. This query returns raw samples for time series with theupname on the time range(2024-01-02T02:00:00 .. 2024-01-02T03:00:00]. See this article for details.
Data replication can be used for increasing storage durability. See these docs for details.
Multi-level cluster setup #
vmselect nodes can be queried by other vmselect nodes if they run with -clusternativeListenAddr command-line flag.
For example, if vmselect is started with -clusternativeListenAddr=:8401, then it can accept queries from another vmselect nodes at TCP port 8401
in the same way as vmstorage nodes do. This allows chaining vmselect nodes and building multi-level cluster topologies.
For example, the top-level vmselect node can query second-level vmselect nodes in different availability zones (AZ),
while the second-level vmselect nodes can query vmstorage nodes in local AZ. See also
vmstorage groups at vmselect
.
vminsert nodes can accept data from another vminsert nodes if they run with -clusternativeListenAddr command-line flag.
For example, if vminsert is started with -clusternativeListenAddr=:8400, then it can accept data from another vminsert nodes at TCP port 8400
in the same way as vmstorage nodes do. This allows chaining vminsert nodes and building multi-level cluster topologies.
For example, the top-level vminsert node can replicate data among the second level of vminsert nodes located in distinct availability zones (AZ),
while the second-level vminsert nodes can spread the data among vmstorage nodes in local AZ.
The multi-level cluster setup for vminsert nodes has the following shortcomings because of synchronous replication and data sharding:
- Data ingestion speed is limited by the slowest link to AZ.
vminsertnodes at top level re-route incoming data to the remaining AZs when some AZs are temporarily unavailable. This results in data gaps at AZs which were temporarily unavailable.
These issues are addressed by
vmagent
when it runs in front of AZs
to
replicate
or
shard
data stream. If AZ is temporarily unavailable, vmagent
buffers
its data on-disk (see --remoteWrite.maxDiskUsagePerURL) without affecting other destinations. The buffered data is sent to AZ as soon as it becomes available.
See the cluster instability troubleshooting guide for details on diagnosing and mitigating networking problems.
vmstorage groups at vmselect #
vmselect can be configured to query multiple distinct groups of vmstorage nodes with individual -replicationFactor per each group.
The following format for -storageNode command-line flag value should be used for assigning a particular addr of vmstorage to a particular groupName -
-storageNode=groupName/addr. The groupName can contain arbitrary value. The only rule is that every vmstorage group must have an unique name.
For example, the following command runs vmselect, which continues returning full responses if up to one node per each group is temporarily unavailable
because the given -replicationFactor=2 is applied individually per each group:
/path/to/vmselect \
-replicationFactor=2 \
-storageNode=g1/host1,g1/host2,g1/host3 \
-storageNode=g2/host4,g2/host5,g2/host6 \
-storageNode=g3/host7,g3/host8,g3/host9
It is possible specifying distinct -replicationFactor per each group via the following format - -replicationFactor=groupName:rf.
For example, the following command runs vmselect, which uses -replicationFactor=3 for the group g1, -replicationFactor=2 for the group g2
and -replicationFactor=1 for the group g3:
/path/to/vmselect \
-replicationFactor=g1:3 \
-storageNode=g1/host1,g1/host2,g1/host3 \
-replicationFactor=g2:2 \
-storageNode=g2/host4,g2/host5,g2/host6 \
-replicationFactor=g3:1 \
-storageNode=g3/host4,g3/host5,g3/host6
If every ingested sample is replicated across multiple vmstorage groups, then pass -globalReplicationFactor=N command-line flag to vmselect,
so it could continue returning full responses if up to N-1 vmstorage groups are temporarily unavailable.
For example, the following command runs vmselect, which continues returning full responses if any number of vmstorage nodes
in a single vmstorage group are temporarily unavailable:
/path/to/vmselect \
-globalReplicationFactor=2 \
-storageNode=g1/host1,g1/host2,g1/host3 \
-storageNode=g2/host4,g2/host5,g2/host6 \
-storageNode=g3/host7,g3/host8,g3/host9
It is OK to mix -replicationFactor and -globalReplicationFactor. For example, the following command runs vmselect, which continues returning full responses
if any number of vmstorage nodes in a single vmstorage group are temporarily unavailable and the remaining groups contain up to two unavailable vmstorage node:
/path/to/vmselect \
-globalReplicationFactor=2 \
-replicationFactor=3 \
-storageNode=g1/host1,g1/host2,g1/host3 \
-storageNode=g2/host4,g2/host5,g2/host6 \
-storageNode=g3/host7,g3/host8,g3/host9
See also multi-level cluster setup .
Automatic vmstorage discovery #
vminsert and vmselect components in
enterprise version of VictoriaMetrics
support
the following approaches for automatic discovery of vmstorage nodes:
file-based discovery - put the list of
vmstoragenodes into a file - one node address per each line - and then pass-storageNode=file:/path/to/file-with-vmstorage-listtovminsertandvmselect. It is possible to read the list of vmstorage nodes from http or https urls. For example,-storageNode=file:http://some-host/vmstorage-listwould read the list of storage nodes fromhttp://some-host/vmstorage-list. The list of discoveredvmstoragenodes is automatically updated when the file contents changes. The update frequency can be controlled with-storageNode.discoveryIntervalcommand-line flag.DNS SRV - pass
srv+some-namevalue to-storageNodecommand-line flag. In this case the providedsome-nameis resolved into tcp addresses ofvmstoragenodes. The list of discoveredvmstoragenodes is automatically updated atvminsertandvmselectwhen it changes behind thesome-nameDNS SRV record. The update frequency can be controlled with-storageNode.discoveryIntervalcommand-line flag.
It is possible passing multiple file and DNS SRV names to -storageNode command-line flag. In this case all these names
are resolved to tcp addresses of vmstorage nodes to connect to.
For example, -storageNode=file:/path/to/local-vmstorage-list -storageNode='srv+vmstorage-hot' -storageNode='srv+vmstorage-cold'.
It is OK to pass regular static vmstorage addresses together with file and DNS SRV addresses at -storageNode. For example,
-storageNode=vmstorage1,vmstorage2 -storageNode='srv+vmstorage-autodiscovery'.
The discovered addresses can be filtered with optional -storageNode.filter command-line flag, which can contain arbitrary regular expression filter.
For example, -storageNode.filter='^[^:]+:8400$' would leave discovered addresses ending with 8400 port only, e.g. the default port used
for sending data from vminsert to vmstorage node according to -vminsertAddr command-line flag.
The currently discovered vmstorage nodes can be
monitored
with vm_rpc_vmstorage_is_reachable and vm_rpc_vmstorage_is_read_only metrics.
Discovery mechanism could be also used together with vmstorage group . Consider the following example:
/path/to/vmselect \
-globalReplicationFactor=2 \
-storageNode=g1/file:/path/to/file-with-vmstorage-list/ \ # Group g1: static list from file
-storageNode=g2/srv+vmstorage-autodiscovery \ # Group g2: nodes discovered dynamically via SRV records
-storageNode=g3/host7,g3/host8,g3/host9 # Group g3: statically defined hostnames
Each -storageNode parameter assigns one or more storage nodes to a specific group (e.g., g1, g2, g3).
The automatically discovered nodes retain the
vmstorage group
prefix to maintain consistent group mapping.
Environment variables #
See these docs .
Security #
General security recommendations:
- All the VictoriaMetrics cluster components must run in protected private network without direct access from untrusted networks such as Internet.
- External clients must access
vminsertandvmselectvia auth proxy such as vmauth or vmgateway . - The auth proxy must accept auth tokens from untrusted networks only via https in order to protect the auth tokens from MitM attacks.
- It is recommended using distinct auth tokens for distinct tenants in order to reduce potential damage in case of compromised auth token for some tenants.
- Prefer using lists of allowed
API endpoints
, while disallowing access to other endpoints when configuring auth proxy in front of
vminsertandvmselect. This minimizes attack surface.
See also security recommendation for single-node VictoriaMetrics and the general security page at VictoriaMetrics website .
mTLS protection #
By default vminsert and vmselect nodes accept http requests at 8480 and 8481 ports accordingly (these ports can be changed via -httpListenAddr command-line flags),
since it is expected that
vmauth
is used for authorization and TLS termination
in front of vminsert and vmselect.
Enterprise version of VictoriaMetrics
supports the ability to accept mTLS
requests at 8480 and 8481 ports for vminsert and vmselect nodes, by specifying -tls and -mtls command-line flags.
For example, the following command runs vmselect, which accepts only mTLS requests at port 8481:
./vmselect -tls -mtls
By default, system-wide TLS Root CA
is used for verifying client certificates if -mtls command-line flag is specified.
It is possible to specify custom TLS Root CA via -mtlsCAFile command-line flag.
By default vminsert and vmselect nodes use unencrypted connections to vmstorage nodes, since it is assumed that all the cluster components
run in a protected environment
.
Enterprise version of VictoriaMetrics
provides optional support for mTLS connections
between cluster components. Pass -cluster.tls=true command-line flag to vminsert, vmselect and vmstorage nodes in order to enable mTLS protection. Additionally, vminsert, vmselect and vmstorage must be configured with mTLS certificates via -cluster.tlsCertFile, -cluster.tlsKeyFile command-line options. These certificates are mutually verified when vminsert and vmselect dial vmstorage.
The following optional command-line flags related to mTLS are supported:
-cluster.tlsInsecureSkipVerifycan be set atvminsert,vmselectandvmstoragein order to disable peer certificate verification. Note that this breaks security.-cluster.tlsCAFilecan be set atvminsert,vmselectandvmstoragefor verifying peer certificates issued with custom certificate authority . By default, system-wide certificate authority is used for peer certificate verification.-cluster.tlsCipherSuitescan be set to the list of supported TLS cipher suites atvmstorage. See the list of supported TLS cipher suites .
When vmselect or vminsert runs with -clusternativeListenAddr command-line option, then it can be configured with -clusternative.tls* options similar to -cluster.tls* for accepting mTLS connections from top-level vmselect or vminsert nodes in
multi-level cluster setup
.
See these docs on how to set up mTLS in VictoriaMetrics cluster.
Enterprise version of VictoriaMetrics can be downloaded and evaluated for free from the releases page . See how to request a free trial license .
Monitoring #
All the cluster components expose various metrics
in Prometheus-compatible format at /metrics page on the TCP port set in -httpListenAddr command-line flag.
By default, the following TCP ports are used:
vminsert- 8480vmselect- 8481vmstorage- 8482
Prefer giving distinct scrape job names per each component type. I.e. vmstorage, vminsert and vmselect should have corresponding job names.
Use the official Grafana dashboard for VictoriaMetrics cluster .
See more details on how to monitor VictoriaMetrics components .
Cardinality limiter #
vmstorage nodes can be configured with limits on the number of unique time series across all the tenants with the following command-line flags:
-storage.maxHourlySeriesis the limit on the number of active time series during the last hour.-storage.maxDailySeriesis the limit on the number of unique time series during the day. This limit can be used for limiting daily time series churn rate .
It is possible to use -1 as a value for these flags
Available from v1.140.0
in order to enable series tracking but set limit to maximum possible value.
This is useful in order to estimate the number of unique series written to vmstorage without enforcing limits.
Note that these limits are set and applied individually per each vmstorage node in the cluster. So, if the cluster has N vmstorage nodes, then the cluster-level limits will be N times bigger than the per-vmstorage limits.
See more details about cardinality limiter in these docs .
Troubleshooting #
- If your VictoriaMetrics cluster experiences data ingestion delays during rolling restarts and configuration updates , then see these docs .
Troubleshooting docs for single-node VictoriaMetrics apply to VictoriaMetrics cluster as well.
Readonly mode #
vmstorage nodes automatically switch to readonly mode when the directory pointed by -storageDataPath
contains less than -storage.minFreeDiskSpaceBytes of free space. vminsert nodes stop sending data to such nodes
and start re-routing the data to the remaining vmstorage nodes.
vmstorage sets vm_storage_is_read_only metric at http://vmstorage:8482/metrics to 1 when it enters read-only mode.
The metric is set to 0 when the vmstorage isn’t in read-only mode.
URL format #
The main differences between URL formats of cluster and
Single server
versions are that cluster has separate components for read and ingestion path, and because of multi-tenancy support.
Also in the cluster version the /prometheus/api/v1 endpoint ingests jsonl, csv, native and prometheus data formats not only prometheus data.
Check practical examples of VictoriaMetrics API .
URLs for data ingestion:
http://<vminsert>:8480/insert/<accountID>/<suffix>, where:<accountID>is an arbitrary 32-bit integer identifying namespace for data ingestion (aka tenant). It is possible to set it asaccountID:projectID, whereprojectIDis also arbitrary 32-bit integer. IfprojectIDisn’t set, then it equals to0. See multitenancy docs for more details about managing tenants, specifying tenant IDs via HTTP headers or labels.<suffix>may have the following values:prometheusandprometheus/api/v1/write- for ingesting data with Prometheus remote write API .prometheus/api/v1/import- for importing data obtained viaapi/v1/exportatvmselect(see below), JSON line format.prometheus/api/v1/import/native- for importing data obtained viaapi/v1/export/nativeonvmselect(see below).prometheus/api/v1/import/csv- for importing arbitrary CSV data. See these docs for details.prometheus/api/v1/import/prometheus- for importing data in Prometheus text exposition format and in OpenMetrics format . This endpoint also supports Pushgateway protocol . See these docs for details.opentelemetry/v1/metrics- for ingesting data via OpenTelemetry protocol for metrics . See these docs .datadog/api/v1/series- for ingesting data with DataDog submit metrics API v1. See these docs for details.datadog/api/v2/series- for ingesting data with DataDog submit metrics API . See these docs for details.datadog/api/beta/sketches- for ingesting data with DataDog lambda extension .influx/writeandinflux/api/v2/write- for ingesting data with InfluxDB line protocol . TCP and UDP receiver is disabled by default. It is exposed on a distinct TCP address set via-influxListenAddrcommand-line flag. See these docs for details.newrelic/infra/v2/metrics/events/bulk- for accepting data from NewRelic infrastructure agent . See these docs for details.opentsdb/api/put- for accepting OpenTSDB HTTP /api/put requests . This handler is disabled by default. It is exposed on a distinct TCP address set via-opentsdbHTTPListenAddrcommand-line flag. See these docs for details.
URLs for Prometheus querying API :
http://<vmselect>:8481/select/<accountID>/prometheus/<suffix>, where:<accountID>is an arbitrary number identifying data namespace for the query (aka tenant). See multitenancy docs for more details about managing tenants, specifying tenant IDs via HTTP headers or labels.<suffix>may have the following values:api/v1/query- performs PromQL instant query .api/v1/query_range- performs PromQL range query .api/v1/series- performs series query .api/v1/labels- returns a list of label names .api/v1/label/<label_name>/values- returns values for the given<label_name>according to the API .federate- returns federated metrics .api/v1/export- exports raw data in JSON line format. See this article for details.api/v1/export/native- exports raw data in native binary format. It may be imported into another VictoriaMetrics viaapi/v1/import/native(see above).api/v1/export/csv- exports data in CSV. It may be imported into another VictoriaMetrics viaapi/v1/import/csv(see above).api/v1/series/count- returns the total number of series.api/v1/status/tsdb- for time series stats. See these docs for details.api/v1/status/active_queries- for currently executed active queries. Note that everyvmselectmaintains an independent list of active queries, which is returned in the response.api/v1/status/top_queries- for listing the most frequently executed queries and queries taking the most duration.api/v1/metadata- for fetching metrics metadata . See these docs for more details.metric-relabel-debug- for debugging relabeling rules .
URLs for Graphite Metrics API :
http://<vmselect>:8481/select/<accountID>/graphite/<suffix>, where:<accountID>is an arbitrary number identifying data namespace for query (aka tenant). See multitenancy docs for more details about managing tenants, specifying tenant IDs via HTTP headers or labels.<suffix>may have the following values:render- implements Graphite Render API. See these docs .metrics/find- searches Graphite metrics. See these docs .metrics/expand- expands Graphite metrics. See these docs .metrics/index.json- returns all the metric names. See these docs .tags/tagSeries- registers time series. See these docs .tags/tagMultiSeries- register multiple time series. See these docs .tags- returns tag names. See these docs .tags/<tag_name>- returns tag values for the given<tag_name>. See these docs .tags/findSeries- returns series matching the givenexpr. See these docs .tags/autoComplete/tags- returns tags matching the giventagPrefixand/orexpr. See these docs .tags/autoComplete/values- returns tag values matching the givenvaluePrefixand/orexpr. See these docs .tags/delSeries- deletes series matching the givenpath. See these docs .
URL with basic Web UI:
http://<vmselect>:8481/select/<accountID>/vmui/.URL for query stats across all tenants:
http://<vmselect>:8481/api/v1/status/top_queries. It lists with the most frequently executed queries and queries taking the most duration.URL for time series deletion:
http://<vmselect>:8481/delete/<accountID>/prometheus/api/v1/admin/tsdb/delete_series?match[]=<timeseries_selector_for_delete>. Note that thedelete_serieshandler should be used only in exceptional cases such as deletion of accidentally ingested incorrect time series. It shouldn’t be used on a regular basis, since it carries non-zero overhead.URL for listing tenants with the ingested data on the given time range:
http://<vmselect>:8481/admin/tenants?start=...&end=.... Thestartandendquery args are optional. If they are missing, then all the tenants with at least one sample stored in VictoriaMetrics are returned.URL for accessing vmalerts UI:
http://<vmselect>:8481/select/<accountID>/prometheus/vmalert/. This URL works only when-vmalert.proxyURLflag is set. See more about vmalert .vmstoragenodes provide the following HTTP endpoints on8482port:/internal/force_merge- initiate forced compactions on the givenvmstoragenode./internal/force_flush- flush in-memory buffers for recently ingested samples into searchable parts on the givenvmstoragenode./snapshot/create- create instant snapshot , which can be used for backups in background. Snapshots are created in<storageDataPath>/snapshotsfolder, where<storageDataPath>is the corresponding command-line flag value./snapshot/list- list available snapshots./snapshot/delete?snapshot=<id>- delete the given snapshot./snapshot/delete_all- delete all the snapshots.
Snapshots may be created independently on each
vmstoragenode. There is no need in synchronizing snapshots’ creation acrossvmstoragenodes.
Cluster resizing and scalability #
Cluster performance and capacity can be scaled up in two ways:
- By adding more resources (CPU, RAM, disk IO, disk space, network bandwidth) to existing nodes in the cluster (aka vertical scalability).
- By adding more nodes to the cluster (aka horizontal scalability).
General recommendations for cluster scalability:
Adding more CPU and RAM to existing
vmselectnodes improves the performance for heavy queries, which process big number of time series with big number of raw samples. See this article on how to detect and optimize heavy queries .Adding more
vmstoragenodes (aka horizontal scaling) increases the number of active time series the cluster can handle. This also increases query performance over time series with high churn rate , since everyvmstoragenode contains lower number of time series when the number ofvmstoragenodes increases.The cluster stability is also improved with the number of
vmstoragenodes, since activevmstoragenodes need to handle lower additional workload when some ofvmstoragenodes become unavailable. For example, if one node out of 3 nodes is unavailable, then1/3=33%of the load is re-distributed across 2 remaining nodes, so per-node workload increase is(1/3/2)/(1/3) = 1/2 = 50%. If one node out of 10 nodes is unavailable, then1/10=10%of the load is re-distributed across 9 remaining nodes, so per-node workload increase is(1/10/9)/(1/10) = 1/9 =~ 11%.Adding more CPU and RAM to existing
vmstoragenodes (aka vertical scaling) increases the number of active time series the cluster can handle. It is preferred to add morevmstoragenodes over adding more CPU and RAM to existingvmstoragenodes, since higher number ofvmstoragenodes increases cluster stability and improves query performance over time series with high churn rate .Adding more
vminsertnodes increases the maximum possible data ingestion speed, since the ingested data may be split among bigger number ofvminsertnodes.Adding more
vmselectnodes increases the maximum possible queries rate, since the incoming concurrent requests may be split among bigger number ofvmselectnodes.
Steps to add vmstorage node:
- Start new
vmstoragenode with the same-retentionPeriodas existing nodes in the cluster. - Gradually restart all the
vmselectnodes with new-storageNodearg containing<new_vmstorage_host>. - Gradually restart all the
vminsertnodes with new-storageNodearg containing<new_vmstorage_host>.
In order to handle uneven disk space usage distribution after adding new vmstorage node it is possible to update vminsert configuration to route newly ingested metrics only to new storage nodes. Once disk usage will be similar configuration can be updated to include all nodes again. Note that vmselect nodes need to reference all storage nodes for querying.
Updating / reconfiguring cluster nodes #
All the node types - vminsert, vmselect and vmstorage - may be updated via graceful shutdown.
Send SIGINT signal to the corresponding process, wait until it finishes and then start new version
with new configs.
There are the following cluster update / upgrade approaches exist:
No downtime strategy #
Gracefully restart every node in the cluster one-by-one with the updated config / upgraded binary.
It is recommended restarting the nodes in the following order:
- Restart
vmstoragenodes. - Restart
vminsertnodes. - Restart
vmselectnodes.
This strategy allows upgrading the cluster without downtime if the following conditions are met:
- The cluster has at least a pair of nodes of each type -
vminsert,vmselectandvmstorage, so it can continue to accept new data and serve incoming requests when a single node is temporary unavailable during its restart. See cluster availability docs for details. - The cluster has enough compute resources (CPU, RAM, network bandwidth, disk IO) for processing
the current workload when a single node of any type (
vminsert,vmselectorvmstorage) is temporarily unavailable during its restart. - The updated config / upgraded binary is compatible with the remaining components in the cluster. See the CHANGELOG for compatibility notes between different releases.
If at least a single condition isn’t met, then the rolling restart may result in cluster unavailability during the config update / version upgrade. In this case the following strategy is recommended.
Minimum downtime strategy #
- Gracefully stop all the
vminsertandvmselectnodes in parallel. - Gracefully restart all the
vmstoragenodes in parallel. - Start all the
vminsertandvmselectnodes in parallel.
The cluster is unavailable for data ingestion and querying when performing the steps above.
The downtime is minimized by restarting cluster nodes in parallel at every step above.
The minimum downtime strategy has the following benefits comparing to no downtime strategy:
- It allows performing config update / version upgrade with minimum disruption when the previous config / version is incompatible with the new config / version.
- It allows performing config update / version upgrade with minimum disruption when the cluster has no enough compute resources (CPU, RAM, disk IO, network bandwidth) for rolling upgrade.
- It allows minimizing the duration of config update / version upgrade for clusters with big number of nodes
of for clusters with big
vmstoragenodes, which may take long time for graceful restart.
If you’d prefer to avoid managing cluster upgrades yourself, VictoriaMetrics Cloud handles version upgrades automatically during maintenance windows, and lets you create, resize, or delete deployments with a few clicks from the UI. See the VictoriaMetrics Cloud documentation to get started.
Improving re-routing performance during restart #
vmstorage nodes may experience increased usage for CPU, RAM and disk IO during
rolling restarts
,
since they need to process higher load when some of vmstorage nodes are temporarily unavailable in the cluster.
The following approaches can be used for reducing resource usage at vmstorage nodes during rolling restart:
To pass
-disableReroutingOnUnavailablecommand-line flag tovminsertnodes, so they pause data ingestion whenvmstoragenodes are restarted instead of re-routing the ingested data to other availablevmstoragenodes. Note that the-disableReroutingOnUnavailableflag may pause data ingestion for long time when somevmstoragenodes are unavailable for long time.To pass bigger values to
-storage.vminsertConnsShutdownDuration(available from v1.95.0 ) command-line flag atvmstoragenodes.In this casevmstorageincreases the interval between gradual closing ofvminsertconnections during graceful shutdown. This reduces data ingestion slowdown during rollout restarts.Make sure that the
-storage.vminsertConnsShutdownDurationis smaller than the graceful shutdown timeout configured at the system which managesvmstorage(e.g. Docker, Kubernetes, systemd, etc.). Otherwise the system may killvmstoragenode before it finishes gradual closing ofvminsertconnections.
See also minimum downtime strategy .
Slowness-based re-routing #
By default, vminsert nodes limit the cluster’s overall ingestion rate to the throughput of the slowest vmstorage node.
This ensures that incoming metrics are evenly distributed across all vmstorage nodes.
The downside is that a single slow vmstorage node can throttle the entire cluster.
When -disableRerouting=false is enabled on vminsert,
the cluster will automatically re-route writes away from the slowest vmstorage node to preserve maximum ingestion throughput.
Re-routing occurs only when all of the following conditions hold:
- the storage send buffer is full.
- the saturated vmstorage node is the slowest.
- the vmstorage cluster have much lower saturation overall.
- the vmstorage cluster has at least three ready nodes.
Enable slowness-based re-routing when peak write throughput matters more than minimizing the number of active time series or keeping metrics perfectly balanced across nodes.
The rerouting and node saturation could be seen at VictoriaMetrics - cluster dashboard.
Capacity planning #
VictoriaMetrics uses lower amounts of CPU, RAM and storage space on production workloads compared to competing solutions (Prometheus, Thanos, Cortex, TimescaleDB, InfluxDB, QuestDB, M3DB) according to our case studies .
Each node type - vminsert, vmselect and vmstorage - can run on the most suitable hardware. Cluster capacity scales linearly with the available resources. The needed amounts of CPU and RAM per each node type highly depends on the workload - the number of
active time series
,
series churn rate
, query types, query qps, etc. It is recommended to setup a test VictoriaMetrics cluster for your production workload and iteratively scale per-node resources and the number of nodes per node type until the cluster becomes stable. It is recommended to setup
monitoring for the cluster
. It helps to determine bottlenecks in the cluster setup. It is also recommended to follow
the troubleshooting docs
.
The needed storage space for the given retention (the retention is set via -retentionPeriod command-line flag at vmstorage) can be extrapolated from disk space usage in a test run. For example, if the storage space usage is 10GB after a day-long test run on a production workload, then it will need at least 10GB*100=1TB of disk space for -retentionPeriod=100d (100-days retention period). Storage space usage can be monitored with
the official Grafana dashboard for VictoriaMetrics cluster
.
It is recommended leaving the following amounts of spare resources:
- 50% of free RAM across all the node types for reducing the probability of OOM (out of memory) crashes and slowdowns during temporary spikes in workload.
- 50% of spare CPU across all the node types for reducing the probability of slowdowns during temporary spikes in workload.
- At least 20% of free storage space at the directory pointed by
-storageDataPathcommand-line flag atvmstoragenodes. See also-storage.minFreeDiskSpaceBytescommand-line flag description for vmstorage .
Increase free storage space and -storage.minFreeDiskSpaceBytes to match at least the amount of data you plan to ingest in a calendar month: on each vmstorage pod, the monthly final deduplication process will temporarily need as much space as is used for the previous month’s data, before it can free up space. For example, if you have a 3 month retention period and you want to keep at least 10 % space free at all times, you could pick 35 % of your total space as value. When some of your vmstorage pods are in
read-only mode
, the remaining pods will have a higher share of the total data ingestion, and will therefore need more free space the next month.
Some capacity planning tips for VictoriaMetrics cluster:
- The
replication
increases the amounts of needed resources for the cluster by up to
Ntimes whereNis replication factor. This is becausevminsertstoresNcopies of every ingested sample on distinctvmstoragenodes. These copies are de-duplicated byvmselectduring querying. The most cost-efficient and performant solution for data durability is to rely on replicated durable persistent disks such as Google Compute persistent disks instead of using the replication at VictoriaMetrics level . - It is recommended to run a cluster with big number of small
vmstoragenodes instead of a cluster with small number of bigvmstoragenodes. This increases chances that the cluster remains available and stable when some ofvmstoragenodes are temporarily unavailable during maintenance events such as upgrades, configuration changes or migrations. For example, when a cluster contains 10vmstoragenodes and a single node becomes temporarily unavailable, then the workload on the remaining 9 nodes increases by1/9=11%. When a cluster contains 3vmstoragenodes and a single node becomes temporarily unavailable, then the workload on the remaining 2 nodes increases by1/2=50%. The remainingvmstoragenodes may have no enough free capacity for handling the increased workload. In this case the cluster may become overloaded, which may result to decreased availability and stability. - Cluster capacity for
active time series
can be increased by increasing RAM and CPU resources per each
vmstoragenode or by adding newvmstoragenodes. - Query latency can be reduced by increasing CPU resources per each
vmselectnode, since each incoming query is processed by a singlevmselectnode. Performance for heavy queries scales with the number of available CPU cores atvmselectnode, sincevmselectprocesses time series referred by the query on all the available CPU cores. - If the cluster needs to process incoming queries at a high rate, then its capacity can be increased by adding more
vmselectnodes, so incoming queries could be spread among bigger number ofvmselectnodes. - By default
vmstoragecompresses the data it sends tovmselectduring queries in order to reduce network bandwidth usage. The compression takes additional CPU resources atvmstorage. Ifvmstoragenodes have limited CPU, then the compression can be disabled by passing-rpc.disableCompressioncommand-line flag atvmstoragenodes.
See also resource usage limits docs .
Rebalancing #
Every vminsert node evenly spreads (shards) incoming data among vmstorage nodes specified in the -storageNode command-line flag.
This guarantees even distribution of the ingested data among vmstorage nodes. When new vmstorage nodes are added to the -storageNode
command-line flag at vminsert, then only newly ingested data is distributed evenly among old and new vmstorage nodes, while
historical data remains on the old vmstorage nodes. This speeds up data ingestion and querying for the majority of production workloads,
since newly ingested data is evenly distributed among all the vmstorage nodes, while querying is usually performed over recently ingested data,
which is already stored among all the vmstorage nodes. This also provides the following benefits:
- Cluster availability and performance remains stable just after adding new
vmstoragenodes, since network bandwidth, disk IO and CPU isn’t spent on data rebalancing amongvmstoragenodes. - This eliminates all the possible hard-to-troubleshoot failures which may happen during automatic data rebalancing.
For example, what happens when some of
vmstoragenodes become unavailable during data rebalancing? Or what happens if newvmstoragenodes are added to the cluster while the previous data rebalancing isn’t finished yet? - This allows building flexible cluster schemes when distinct subsets of
vminsertnodes distribute incoming data among different subsets ofvmstoragenodes with different configs and hardware resources.
There are the following approaches exist for data rebalancing among old and new vmstorage nodes:
- To wait until historical data on the old
vmstoragenodes is automatically deleted according to the configured retention . - To pass only new
vmstorageaddresses to-storageNodecommand-line flag atvminsertnodes, while passing all thevmstorageaddresses to-storageNodecommand-line flag atvmselectnodes. This enables writing new data only to newvmstoragenodes, while historical data from oldvmstoragenodes remain available for querying viavmselecttogether with the newly ingested data. Then wait until data sizes among old and newvmstoragenodes become equal and then add oldvmstoragenodes the-storageNodecommand-line flag atvminsertnodes.
See also capacity planning docs and Why VictoriaMetrics misses automatic data re-balancing among vmstorage nodes? .
Resource usage limits #
By default, cluster components of VictoriaMetrics are tuned for an optimal resource usage under typical workloads. Some workloads may need fine-grained resource usage limits. In these cases the following command-line flags may be useful:
-memory.allowedPercentand-memory.allowedByteslimit the amounts of memory, which may be used for various internal caches at all the cluster components of VictoriaMetrics -vminsert,vmselectandvmstorage. Note that VictoriaMetrics components may use more memory, since these flags don’t limit additional memory, which may be needed on a per-query basis.-search.maxMemoryPerQuerylimits the amounts of memory, which can be used for processing a single query atvmselectnode. Queries, which need more memory, are rejected. Heavy queries, which select big number of time series, may exceed the per-query memory limit by a small percent. The total memory limit for concurrently executed queries can be estimated as-search.maxMemoryPerQuerymultiplied by-search.maxConcurrentRequests.-search.maxUniqueTimeseriesatvmstoragecomponent limits the number of unique time series a single query can find and process. This means that the maximum memory usage and CPU usage a single query can use atvmstorageis proportional to-search.maxUniqueTimeseries. By default,vmstoragecalculates this limit automatically based on the available memory and the maximum number of concurrent read requests (see-search.maxConcurrentRequests). The calculated limit will be printed during process start-up logs and exposed asvm_search_max_unique_timeseriesmetric.-search.maxUniqueTimeseriesatvmselectadjusts the limit with the same name atvmstorage. The limit cannot exceed the value set in vmstorage if the-search.maxUniqueTimeseriesflag is explicitly defined there. By default, vmselect doesn’t apply limit adjustments.-search.maxQueryDurationatvmselectlimits the duration of a single query. If the query takes longer than the given duration, then it is canceled. This allows saving CPU and RAM atvmselectandvmstoragewhen executing unexpectedly heavy queries. The limit can be overridden to a smaller value by passingtimeoutGET parameter.-search.maxConcurrentRequestsatvmselectandvmstoragelimits the number of concurrent requests a singlevmselect/vmstoragenode can process. Bigger number of concurrent requests usually require bigger amounts of memory at bothvmselectandvmstorage. For example, if a single query needs 100 MiB of additional memory during its execution, then 100 concurrent queries may need100 * 100 MiB = 10 GiBof additional memory. So it is better to limit the number of concurrent queries, while pausing additional incoming queries if the concurrency limit is reached.vmselectandvmstorageprovides-search.maxQueueDurationcommand-line flag for limiting the maximum wait time for paused queries. See also-search.maxMemoryPerQuerycommand-line flag atvmselect.-search.maxQueueDurationatvmselectandvmstoragelimits the maximum duration queries may wait for execution when-search.maxConcurrentRequestsconcurrent queries are executed.-search.ignoreExtraFiltersAtLabelsAPIatvmselectenables ignoring ofmatch[],extra_filters[]andextra_labelquery args at /api/v1/labels and /api/v1/label/…/values . This may be useful for reducing the load onvmstorageif the provided extra filters match too many time series. The downside is that the endpoints can return labels and series, which do not match the provided extra filters.-search.maxSamplesPerSeriesatvmselectlimits the number of raw samples the query can process per each time series.vmselectprocesses raw samples sequentially per each found time series during the query. It unpacks raw samples on the selected time range per each time series into memory and then applies the given rollup function . The-search.maxSamplesPerSeriescommand-line flag allows limiting memory usage atvmselectin the case when the query is executed on a time range, which contains hundreds of millions of raw samples per each located time series.-search.maxSamplesPerQueryatvmselectlimits the number of raw samples a single query can process. This allows limiting CPU usage atvmselectfor heavy queries.-search.maxResponseSeriesatvmselectlimits the number of time series a single query can return from/api/v1/queryand/api/v1/query_range.-search.maxPointsPerTimeserieslimits the number of calculated points, which can be returned per each matching time series from range query .-search.maxPointsSubqueryPerTimeserieslimits the number of calculated points, which can be generated per each matching time series during subquery evaluation.-search.maxSeriesPerAggrFunclimits the number of time series, which can be generated by MetricsQL aggregate functions in a single query.-search.maxSeriesatvmselectlimits the number of time series, which may be returned from /api/v1/series . This endpoint is used mostly by Grafana for auto-completion of metric names, label names and label values. Queries to this endpoint may take big amounts of CPU time and memory atvmstorageandvmselectwhen the database contains big number of unique time series because of high churn rate . In this case it might be useful to set the-search.maxSeriesto quite low value in order limit CPU and memory usage.-search.maxDeleteSeriesatvmselectlimits the number of unique time series that can be deleted by a single /api/v1/admin/tsdb/delete_series call. The duration is limited via-search.maxDeleteDurationflag Available from v1.110.0 . Deleting too many time series may require big amount of CPU and memory atvmstorageand this limit guards against unplanned resource usage spikes. Also see How to delete time series section to learn about different ways of deleting series.-search.maxTSDBStatusTopNSeriesatvmselectlimits the number of unique time series that can be queried with topN argument by a single /api/v1/status/tsdb?topN=N call.-search.maxTagKeysatvmstoragelimits the number of items, which may be returned from /api/v1/labels . This endpoint is used mostly by Grafana for auto-completion of label names. Queries to this endpoint may take big amounts of CPU time and memory atvmstorageandvmselectwhen the database contains big number of unique time series because of high churn rate . In this case it might be useful to set the-search.maxTagKeysto quite low value in order to limit CPU and memory usage. See also-search.maxLabelsAPIDurationand-search.maxLabelsAPISeries.-search.maxTagValuesatvmstoragelimits the number of items, which may be returned from /api/v1/label/…/values . This endpoint is used mostly by Grafana for auto-completion of label values. Queries to this endpoint may take big amounts of CPU time and memory atvmstorageandvmselectwhen the database contains big number of unique time series because of high churn rate . In this case it might be useful to set the-search.maxTagValuesto quite low value in order to limit CPU and memory usage. See also-search.maxLabelsAPIDurationand-search.maxLabelsAPISeries.-search.maxLabelsAPISeriesatvmselectlimits the number of time series, which can be scanned when performing /api/v1/labels or /api/v1/label/…/values requests. These endpoints are used mostly by Grafana for auto-completion of label names and label values. Queries to these endpoints may take big amounts of CPU time and memory when the database contains big number of unique time series because of high churn rate . In this case it might be useful to set the-search.maxLabelsAPISeriesto quite low value in order to limit CPU and memory usage. See also-search.maxLabelsAPIDurationand-search.ignoreExtraFiltersAtLabelsAPI.-search.maxLabelsAPIDurationatvmselectlimits the duration for requests to /api/v1/labels , /api/v1/label/…/values or /api/v1/series . The limit can be overridden to a smaller value by passingtimeoutGET parameter. These endpoints are used mostly by Grafana for auto-completion of label names and label values. Queries to these endpoints may take big amounts of CPU time and memory when the database contains big number of unique time series because of high churn rate . In this case it might be useful to set the-search.maxLabelsAPIDurationto quite low value in order to limit CPU and memory usage. See also-search.maxLabelsAPISeriesand-search.ignoreExtraFiltersAtLabelsAPI.-search.maxFederateSeriesatvmselectlimits maximum number of time series, which can be returned via /federate API . The duration of the/federatequeries is limited via-search.maxQueryDurationflag. This option allows limiting memory usage.-search.maxExportSeriesatvmselectlimits maximum number of time series, which can be returned from /api/v1/export* APIs . The duration of the export queries is limited via-search.maxExportDurationflag. This option allows limiting memory usage.-search.maxTSDBStatusSeriesatvmselectlimits maximum number of time series, which can be processed during the call to /api/v1/status/tsdb . The duration of the status queries is limited via-search.maxStatusRequestDurationflag. This option allows limiting memory usage.-storage.maxDailySeriesatvmstoragecan be used for limiting the number of time series seen per day aka time series churn rate . See cardinality limiter docs .-storage.maxHourlySeriesatvmstoragecan be used for limiting the number of active time series . See cardinality limiter docs .
See also capacity planning docs and cardinality limiter in vmagent .
Helm #
Helm chart simplifies managing cluster version of VictoriaMetrics in Kubernetes. It is available in the helm-charts repository.
Kubernetes operator #
K8s operator simplifies managing VictoriaMetrics components in Kubernetes.
Replication and data safety #
By default, VictoriaMetrics offloads replication to the underlying storage pointed by -storageDataPath such as Google compute persistent disk
,
which guarantees data durability. VictoriaMetrics supports application-level replication if replicated durable persistent disks cannot be used for some reason.
The replication can be enabled by passing -replicationFactor=N command-line flag to vminsert. This instructs vminsert to store N copies for every ingested sample
on N distinct vmstorage nodes. This guarantees that all the stored data remains available for querying if up to N-1 vmstorage nodes are unavailable.
Passing -replicationFactor=N command-line flag to vmselect instructs it to not mark responses as partial if less than -replicationFactor vmstorage nodes are unavailable during the query.
See
cluster availability docs
for details.
The cluster must contain at least 2*N-1 vmstorage nodes, where N is replication factor, in order to maintain the given replication factor
for newly ingested data when N-1 of storage nodes are unavailable.
VictoriaMetrics stores timestamps with millisecond precision, so -dedup.minScrapeInterval=1ms command-line flag must be passed to vmselect nodes when the replication is enabled,
so they could de-duplicate replicated samples obtained from distinct vmstorage nodes during querying. If duplicate data is pushed to VictoriaMetrics
from identically configured
vmagent
instances or Prometheus instances, then the -dedup.minScrapeInterval must be set
to scrape_interval from scrape configs according to
deduplication docs
.
Note that replication doesn’t save from disaster , so it is recommended performing regular backups. See these docs for details.
Note that the replication increases resource usage - CPU, RAM, disk space, network bandwidth - by up to -replicationFactor=N times, because vminsert stores N copies
of incoming data to distinct vmstorage nodes and vmselect needs to de-duplicate the replicated data obtained from vmstorage nodes during querying.
So it is more cost-effective to offload the replication to underlying replicated durable storage pointed by -storageDataPath
such as Google Compute Engine persistent disk
, which is protected from data loss and data corruption.
It also provides consistently high performance and may be resized
without downtime.
HDD-based persistent disks should be enough for the majority of use cases. It is recommended using durable replicated persistent volumes in Kubernetes.
Deduplication #
Cluster version of VictoriaMetrics supports data deduplication in the same way as single-node version do.
See
these docs
for details. The only difference is that
deduplication can’t be guaranteed when samples and sample duplicates for the same time series end up on different
vmstorage nodes. This could happen in the following scenarios:
- when adding/removing
vmstoragenodes a new samples for time series will be re-routed to anothervmstoragenodes; - when
vmstoragenodes are temporarily unavailable (for instance, during their restart). Then new samples are re-routed to the remaining availablevmstoragenodes; - when
vmstoragenode has no enough capacity for processing incoming data stream. Thenvminsertre-routes new samples to othervmstoragenodes.
It is recommended to set the same -dedup.minScrapeInterval command-line flag value to both vmselect and vmstorage nodes
to ensure query results consistency, even if storage layer didn’t complete deduplication yet.
Metrics Metadata #
Cluster version of VictoriaMetrics can store metric metadata (TYPE, HELP, UNIT)
Available from v1.130.0
.
Metadata ingestion is enabled by default
Available from v1.137.0
. To disable it, set -enableMetadata=false on vminsert, and vmagent.
The metadata is cached in-memory in a ring buffer and can use up to 1% of available memory by default (see -storage.maxMetadataStorageSize cmd-line flag).
When in-memory size is exceeded, the least updated entries are dropped first. Entries that weren’t updated for 1h are cleaned up automatically.
The following expression helps to understand if metadata cache capacity is utilized for more than 90%: vm_metrics_metadata_storage_size_bytes / vm_metrics_metadata_storage_max_size_bytes > 0.9.
Setup
monitoring
and recommended alerting rules
to get notified about cache capacity issues.
Metadata is ingested independently from metrics, so a metric can exist without metadata, and vice versa. Metadata is expected to be ephemeral and constantly updated on ingestion. For this reason, metadata cache isn’t persisted during storage restarts.
Metadata supports
multitenancy
and can be queried via the /select/<accountID>/prometheus/api/v1/metadata endpoint, which provides a response compatible with the Prometheus metadata API
.
If multiple vmstorage nodes return metadata for the same metric family name, or if multiple tenants have metadata for the same metric family name, vmselect returns only the first matching result.
Duplicate metadata entries are not merged or deduplicated across storages or tenants. See
/api/v1/metadata
example.
Backups #
For backup configuration, please refer for vmbackup documentation .
Retention filters #
VictoriaMetrics Enterprise
supports configuring multiple retentions for distinct sets of time series
by passing -retentionFilter command-line flag to vmstorage nodes. See
these docs
for details on this feature.
Additionally, enterprise version of VictoriaMetrics cluster supports multiple retentions for distinct sets of
tenants
by specifying filters on vm_account_id and/or vm_project_id pseudo-labels in -retentionFilter command-line flag.
If the tenant doesn’t match specified -retentionFilter options, then the global -retentionPeriod is used for it.
For example, the following config sets retention to 1 day for
tenants
with accountID starting from 42,
then sets retention to 3 days for time series with label env="dev" or env="prod" from any tenant,
while the rest of tenants will have 4 weeks retention:
-retentionFilter='{vm_account_id=~"42.*"}:1d' -retentionFilter='{env=~"dev|staging"}:3d' -retentionPeriod=4w
It is OK to mix filters on real labels with filters on vm_account_id and vm_project_id pseudo-labels.
For example, the following config sets retention to 5 days for time series with env="dev" label from
tenant
accountID=5:
-retentionFilter='{vm_account_id="5",env="dev"}:5d'
See also downsampling .
Enterprise binaries can be downloaded and evaluated for free from the releases page . See how to request a free trial license .
Downsampling #
VictoriaMetrics Enterprise
supports configuring downsampling rules for different time series sets by passing -downsampling.period command-line flag to vmstorage and vmselect nodes. See
these docs
for details.
It is possible to downsample series, which belong to a particular
tenant
by using
filters
on vm_account_id or vm_project_id pseudo-labels in -downsampling.period command-line flag. For example, the following config leaves the last sample per each minute for samples
older than one hour only for
tenants
with accountID equal to 12 and 42, while series for other tenants are dropped:
-downsampling.period='{vm_account_id=~"12|42"}:1h:1m'
It is OK to mix filters on real labels with filters on vm_account_id and vm_project_id pseudo-labels.
For example, the following config instructs leaving the last sample per hour after 30 days for time series with env="dev" label from
tenant
accountID=5:
-downsampling.period='{vm_account_id="5",env="dev"}:30d:1h'
The same flag value must be passed to both vmstorage and vmselect nodes. Configuring vmselect node with -downsampling.period
command-line flag makes query results more consistent, because vmselect uses the maximum configured downsampling interval
on the requested time range if this time range covers multiple downsampling levels.
For example, if -downsampling.period=30d:5m and the query requests the last 60 days of data, then vmselect
downsamples all the
raw samples
on the requested time range
using 5 minute interval. If -downsampling.period command-line flag isn’t set at vmselect,
then query results can be less consistent because of mixing raw and downsampled data.
See also retention filters .
Enterprise binaries can be downloaded and evaluated for free from the releases page . See how to request a free trial license .
Profiling #
All the cluster components provide the following handlers for profiling :
http://vminsert:8480/debug/pprof/heapfor memory profile andhttp://vminsert:8480/debug/pprof/profilefor CPU profilehttp://vmselect:8481/debug/pprof/heapfor memory profile andhttp://vmselect:8481/debug/pprof/profilefor CPU profilehttp://vmstorage:8482/debug/pprof/heapfor memory profile andhttp://vmstorage:8482/debug/pprof/profilefor CPU profile
Example command for collecting cpu profile from vmstorage (replace 0.0.0.0 with vmstorage hostname if needed):
curl http://0.0.0.0:8482/debug/pprof/profile > cpu.pprof
Example command for collecting memory profile from vminsert (replace 0.0.0.0 with vminsert hostname if needed):
curl http://0.0.0.0:8480/debug/pprof/heap > mem.pprof
It is safe sharing the collected profiles from security point of view, since they do not contain sensitive information.
vmalert #
vmselect is capable of proxying requests to
vmalert
when -vmalert.proxyURL flag is set. Use this feature for the following cases:
- for proxying requests from Grafana Alerting UI ;
- for accessing vmalert UI through vmselect Web interface.
For accessing vmalerts UI through vmselect configure -vmalert.proxyURL flag and visit
http://<vmselect>:8481/select/<accountID>/prometheus/vmalert/ link.
Community and contributions #
Feel free asking any questions regarding VictoriaMetrics:
If you like VictoriaMetrics and want contributing, then please read these docs .
Reporting bugs #
Report bugs and propose new features in our GitHub Issues .
List of command-line flags #
- List of command-line flags for vminsert
- List of command-line flags for vmselect
- List of command-line flags for vmstorage
List of command-line flags for vminsert #
Pass -help to vminsert in order to see the list of supported command-line flags with their description.
Common vminsert flags #
These flags are available in both VictoriaMetrics OSS and VictoriaMetrics Enterprise.
vminsert accepts data via popular data ingestion protocols and routes it to vmstorage nodes configured via -storageNode.
See the docs at https://docs.victoriametrics.com/victoriametrics/cluster-victoriametrics/ .
-blockcache.missesBeforeCaching int
The number of cache misses before putting the block into cache. Higher values may reduce indexdb/dataBlocks cache size at the cost of higher CPU and disk read usage (default 2)
-cacheExpireDuration duration
Items are removed from in-memory caches after they aren't accessed for this duration. Lower values may reduce memory usage at the cost of higher CPU usage. See also -prevCacheRemovalPercent (default 30m0s)
-clusternative.vminsertConnsShutdownDuration duration
The time needed for gradual closing of upstream vminsert connections during graceful shutdown. Bigger duration reduces spikes in CPU, RAM and disk IO load on the remaining lower-level clusters during rolling restart. Smaller duration reduces the time needed to close all the upstream vminsert connections, thus reducing the time for graceful shutdown. See https://docs.victoriametrics.com/victoriametrics/cluster-victoriametrics/#improving-re-routing-performance-during-restart (default 25s)
-clusternativeListenAddr string
TCP address to listen for data from other vminsert nodes in multi-level cluster setup. See https://docs.victoriametrics.com/victoriametrics/cluster-victoriametrics/#multi-level-cluster-setup . Usually :8400 should be set to match default vmstorage port for vminsert. Disabled work if empty
-csvTrimTimestamp duration
Trim timestamps when importing csv data to this duration. Minimum practical duration is 1ms. Higher duration (i.e. 1s) may be used for reducing disk space usage for timestamp data (default 1ms)
-datadog.maxInsertRequestSize size
The maximum size in bytes of a single DataDog POST request to /datadog/api/v2/series
Supports the following optional suffixes for size values: KB, MB, GB, TB, KiB, MiB, GiB, TiB (default 67108864)
-datadog.sanitizeMetricName
Sanitize metric names for the ingested DataDog data to comply with DataDog behaviour described at https://docs.datadoghq.com/metrics/custom_metrics/#naming-custom-metrics (default true)
-denyQueryTracing
Whether to disable the ability to trace queries. See https://docs.victoriametrics.com/victoriametrics/single-server-victoriametrics/#query-tracing
-disableRerouting
Whether to disable re-routing when some of vmstorage nodes accept incoming data at slower speed compared to other storage nodes. Disabled re-routing limits the ingestion rate by the slowest vmstorage node. On the other side, disabled re-routing minimizes the number of active time series in the cluster during rolling restarts and during spikes in series churn rate. See also -disableReroutingOnUnavailable and -dropSamplesOnOverload (default true)
-disableReroutingOnUnavailable
Whether to disable re-routing when some of vmstorage nodes are unavailable. Disabled re-routing stops ingestion when some storage nodes are unavailable. On the other side, disabled re-routing minimizes the number of active time series in the cluster during rolling restarts and during spikes in series churn rate. See also -disableRerouting
-dropSamplesOnOverload
Whether to drop incoming samples if the destination vmstorage node is overloaded and/or unavailable. This prioritizes cluster availability over consistency, e.g. the cluster continues accepting all the ingested samples, but some of them may be dropped if vmstorage nodes are temporarily unavailable and/or overloaded. The drop of samples happens before the replication, so it's not recommended to use this flag with -replicationFactor enabled.
-enableMetadata
Whether to enable metadata processing for metrics scraped from targets, received via VictoriaMetrics remote write, Prometheus remote write v1 or OpenTelemetry protocol. See also remoteWrite.maxMetadataPerBlock (default true)
-enableMultitenancyViaHeaders
Enables multitenancy via HTTP headers. See https://docs.victoriametrics.com/victoriametrics/cluster-victoriametrics/#multitenancy-via-headers
-enableTCP6
Whether to enable IPv6 for listening and dialing. By default, only IPv4 TCP and UDP are used
-envflag.enable
Whether to enable reading flags from environment variables in addition to the command line. Command line flag values have priority over values from environment vars. Flags are read only from the command line if this flag isn't set. See https://docs.victoriametrics.com/victoriametrics/single-server-victoriametrics/#environment-variables for more details
-envflag.prefix string
Prefix for environment variables if -envflag.enable is set
-filestream.disableFadvise
Whether to disable fadvise() syscall when reading large data files. The fadvise() syscall prevents from eviction of recently accessed data from OS page cache during background merges and backups. In some rare cases it is better to disable the syscall if it uses too much CPU
-flagsAuthKey value
Auth key for /flags endpoint. It must be passed via authKey query arg. It overrides -httpAuth.*
Flag value can be read from the given file when using -flagsAuthKey=file:///abs/path/to/file or -flagsAuthKey=file://./relative/path/to/file.
Flag value can be read from the given http/https url when using -flagsAuthKey=http://host/path or -flagsAuthKey=https://host/path
-fs.disableMincore
Whether to disable the mincore() syscall for checking mmap()ed files. By default, mincore() is used to detect whether mmap()ed file pages are resident in memory. Disabling mincore() may be needed on older ZFS filesystems (below 2.1.5), since it may trigger ZFS bug. See https://github.com/VictoriaMetrics/VictoriaMetrics/issues/10327 for details.
-fs.disableMmap
Whether to use pread() instead of mmap() for reading data files. By default, mmap() is used for 64-bit arches and pread() is used for 32-bit arches, since they cannot read data files bigger than 2^32 bytes in memory. mmap() is usually faster for reading small data chunks than pread()
-fs.maxConcurrency int
The maximum number of concurrent goroutines to work with files; smaller values may help reducing Go scheduling latency on systems with small number of CPU cores; higher values may help reducing data ingestion latency on systems with high-latency storage such as NFS or Ceph (default fsutil.getDefaultConcurrency())
-graphite.sanitizeMetricName
Sanitize metric names for the ingested Graphite data. See https://docs.victoriametrics.com/victoriametrics/integrations/graphite/#ingesting
-graphiteListenAddr string
TCP and UDP address to listen for Graphite plaintext data. Usually :2003 must be set. Doesn't work if empty. See also -graphiteListenAddr.useProxyProtocol
-graphiteListenAddr.useProxyProtocol
Whether to use proxy protocol for connections accepted at -graphiteListenAddr . See https://www.haproxy.org/download/1.8/doc/proxy-protocol.txt
-graphiteTrimTimestamp duration
Trim timestamps for Graphite data to this duration. Minimum practical duration is 1s. Higher duration (i.e. 1m) may be used for reducing disk space usage for timestamp data (default 1s)
-http.connTimeout duration
Incoming connections to -httpListenAddr are closed after the configured timeout. This may help evenly spreading load among a cluster of services behind TCP-level load balancer. Zero value disables closing of incoming connections (default 2m0s)
-http.disableCORS
Disable CORS for all origins (*)
-http.disableKeepAlive
Whether to disable HTTP keep-alive for incoming connections at -httpListenAddr
-http.disableResponseCompression
Disable compression of HTTP responses to save CPU resources. By default, compression is enabled to save network bandwidth
-http.header.csp string
Value for 'Content-Security-Policy' header, recommended: "default-src 'self'"
-http.header.disableServerHostname
Whether to disable 'X-Server-Hostname' header in HTTP responses
-http.header.frameOptions string
Value for 'X-Frame-Options' header
-http.header.hsts string
Value for 'Strict-Transport-Security' header, recommended: 'max-age=31536000; includeSubDomains'
-http.idleConnTimeout duration
Timeout for incoming idle http connections (default 1m0s)
-http.maxGracefulShutdownDuration duration
The maximum duration for a graceful shutdown of the HTTP server. During this period the server stops accepting new connections, but it will continue serving existing connections. The remaining in-flight requests are canceled before the deadline, so the shutdown can finish within this duration. A highly loaded server may require increased value for a graceful shutdown (default 7s)
-http.pathPrefix string
An optional prefix to add to all the paths handled by http server. For example, if '-http.pathPrefix=/foo/bar' is set, then all the http requests will be handled on '/foo/bar/*' paths. This may be useful for proxied requests. See https://www.robustperception.io/using-external-urls-and-proxies-with-prometheus
-http.shutdownDelay duration
Optional delay before http server shutdown. During this delay, the server returns non-OK responses from /health page, so load balancers can route new requests to other servers
-httpAuth.password value
Password for HTTP server's Basic Auth. The authentication is disabled if -httpAuth.username is empty
Flag value can be read from the given file when using -httpAuth.password=file:///abs/path/to/file or -httpAuth.password=file://./relative/path/to/file.
Flag value can be read from the given http/https url when using -httpAuth.password=http://host/path or -httpAuth.password=https://host/path
-httpAuth.username string
Username for HTTP server's Basic Auth. The authentication is disabled if empty. See also -httpAuth.password
-httpListenAddr array
Address to listen for incoming http requests. See also -httpListenAddr.useProxyProtocol
Supports an array of values separated by comma or specified via multiple flags.
Each array item can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-httpListenAddr.useProxyProtocol array
Whether to use proxy protocol for connections accepted at the given -httpListenAddr . See https://www.haproxy.org/download/1.8/doc/proxy-protocol.txt . With enabled proxy protocol http server cannot serve regular /metrics endpoint. Use -pushmetrics.url for metrics pushing
Supports array of values separated by comma or specified via multiple flags.
Empty values are set to false.
-import.maxLineLen size
The maximum length in bytes of a single line accepted by /api/v1/import; the line length can be limited with 'max_rows_per_line' query arg passed to /api/v1/export
Supports the following optional suffixes for size values: KB, MB, GB, TB, KiB, MiB, GiB, TiB (default 10485760)
-influx.databaseNames array
Comma-separated list of database names to return from /query and /influx/query API. This can be needed for accepting data from Telegraf plugins such as https://github.com/fangli/fluent-plugin-influxdb
Supports an array of values separated by comma or specified via multiple flags.
Each array item can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-influx.forceStreamMode
Force stream mode parsing for ingested data. See https://docs.victoriametrics.com/victoriametrics/integrations/influxdb/
-influx.maxLineSize size
The maximum size in bytes for a single InfluxDB line during parsing. Applicable for stream mode only. See https://docs.victoriametrics.com/victoriametrics/integrations/influxdb/
Supports the following optional suffixes for size values: KB, MB, GB, TB, KiB, MiB, GiB, TiB (default 262144)
-influx.maxRequestSize size
The maximum size in bytes of a single InfluxDB request. Applicable for batch mode only. See https://docs.victoriametrics.com/victoriametrics/integrations/influxdb/
Supports the following optional suffixes for size values: KB, MB, GB, TB, KiB, MiB, GiB, TiB (default 67108864)
-influxDBLabel string
Default label for the DB name sent over '?db={db_name}' query parameter (default "db")
-influxListenAddr string
TCP and UDP address to listen for InfluxDB line protocol data. Usually :8089 must be set. Doesn't work if empty. This flag isn't needed when ingesting data over HTTP - just send it to http://<victoriametrics>:8428/write . See also -influxListenAddr.useProxyProtocol
-influxListenAddr.useProxyProtocol
Whether to use proxy protocol for connections accepted at -influxListenAddr . See https://www.haproxy.org/download/1.8/doc/proxy-protocol.txt
-influxMeasurementFieldSeparator string
Separator for '{measurement}{separator}{field_name}' metric name when inserted via InfluxDB line protocol (default "_")
-influxSkipMeasurement
Uses '{field_name}' as a metric name while ignoring '{measurement}' and '-influxMeasurementFieldSeparator'
-influxSkipSingleField
Uses '{measurement}' instead of '{measurement}{separator}{field_name}' for metric name if InfluxDB line contains only a single field
-influxTrimTimestamp duration
Trim timestamps for InfluxDB line protocol data to this duration. Minimum practical duration is 1ms. Higher duration (i.e. 1s) may be used for reducing disk space usage for timestamp data (default 1ms)
-insert.maxQueueDuration duration
The maximum duration to wait in the queue when -maxConcurrentInserts concurrent insert requests are executed (default 1m0s)
-internStringCacheExpireDuration duration
The expiry duration for caches for interned strings. See https://en.wikipedia.org/wiki/String_interning . See also -internStringMaxLen and -internStringDisableCache (default 6m0s)
-internStringDisableCache
Whether to disable caches for interned strings. This may reduce memory usage at the cost of higher CPU usage. See https://en.wikipedia.org/wiki/String_interning . See also -internStringCacheExpireDuration and -internStringMaxLen
-internStringMaxLen int
The maximum length for strings to intern. A lower limit may save memory at the cost of higher CPU usage. See https://en.wikipedia.org/wiki/String_interning . See also -internStringDisableCache and -internStringCacheExpireDuration (default 500)
-loggerDisableTimestamps
Whether to disable writing timestamps in logs
-loggerErrorsPerSecondLimit int
Per-second limit on the number of ERROR messages. If more than the given number of errors are emitted per second, the remaining errors are suppressed. Zero values disable the rate limit
-loggerFormat string
Format for logs. Possible values: default, json (default "default")
-loggerJSONFields string
Allows renaming fields in JSON formatted logs. Example: "ts:timestamp,msg:message" renames "ts" to "timestamp" and "msg" to "message". Supported fields: ts, level, caller, msg
-loggerLevel string
Minimum level of errors to log. Possible values: INFO, WARN, ERROR, FATAL, PANIC (default "INFO")
-loggerMaxArgLen int
The maximum length of a single logged argument. Longer arguments are replaced with 'arg_start..arg_end', where 'arg_start' and 'arg_end' is prefix and suffix of the arg with the length not exceeding -loggerMaxArgLen / 2 (default 5000)
-loggerOutput string
Output for the logs. Supported values: stderr, stdout (default "stderr")
-loggerTimezone string
Timezone to use for timestamps in logs. Timezone must be a valid IANA Time Zone. For example: America/New_York, Europe/Berlin, Etc/GMT+3 or Local (default "UTC")
-loggerWarnsPerSecondLimit int
Per-second limit on the number of WARN messages. If more than the given number of warns are emitted per second, then the remaining warns are suppressed. Zero values disable the rate limit
-maxConcurrentInserts int
The maximum number of concurrent insert requests. Set higher value when clients send data over slow networks. Default value depends on the number of available CPU cores. It should work fine in most cases since it minimizes resource usage. See also -insert.maxQueueDuration (default 2*cgroup.AvailableCPUs())
-maxInsertRequestSize size
The maximum size in bytes of a single Prometheus remote_write API request
Supports the following optional suffixes for size values: KB, MB, GB, TB, KiB, MiB, GiB, TiB (default 33554432)
-maxLabelNameLen int
The maximum length of label name in the accepted time series. Series with longer label name are ignored. In this case the vm_rows_ignored_total{reason="too_long_label_name"} metric at /metrics page is incremented. Value must be in range 1..65535. (default 256)
-maxLabelValueLen int
The maximum length of label values in the accepted time series. Series with longer label value are ignored. In this case the vm_rows_ignored_total{reason="too_long_label_value"} metric at /metrics page is incremented. Value must be in range 1..65535. (default 4096)
-maxLabelsPerTimeseries int
The maximum number of labels per time series to be accepted. Series with superfluous labels are ignored. In this case the vm_rows_ignored_total{reason="too_many_labels"} metric at /metrics page is incremented (default 40)
-memory.allowedBytes size
Allowed size of system memory VictoriaMetrics caches may occupy. This option overrides -memory.allowedPercent if set to a non-zero value. Too low a value may increase the cache miss rate usually resulting in higher CPU and disk IO usage. Too high a value may evict too much data from the OS page cache resulting in higher disk IO usage. The process may behave unexpectedly if this flag is set too small (e.g., 1 byte).
Supports the following optional suffixes for size values: KB, MB, GB, TB, KiB, MiB, GiB, TiB (default 0)
-memory.allowedPercent float
Allowed percent of system memory VictoriaMetrics caches may occupy. See also -memory.allowedBytes. Too low a value may increase cache miss rate usually resulting in higher CPU and disk IO usage. Too high a value may evict too much data from the OS page cache which will result in higher disk IO usage (default 60)
-metrics.exposeMetadata
Whether to expose TYPE and HELP metadata at the /metrics page, which is exposed at -httpListenAddr . The metadata may be needed when the /metrics page is consumed by systems, which require this information. For example, Managed Prometheus in Google Cloud - https://cloud.google.com/stackdriver/docs/managed-prometheus/troubleshooting#missing-metric-type
-metricsAuthKey value
Auth key for /metrics endpoint. It must be passed via authKey query arg. It overrides -httpAuth.*
Flag value can be read from the given file when using -metricsAuthKey=file:///abs/path/to/file or -metricsAuthKey=file://./relative/path/to/file.
Flag value can be read from the given http/https url when using -metricsAuthKey=http://host/path or -metricsAuthKey=https://host/path
-newrelic.maxInsertRequestSize size
The maximum size in bytes of a single NewRelic request to /newrelic/infra/v2/metrics/events/bulk
Supports the following optional suffixes for size values: KB, MB, GB, TB, KiB, MiB, GiB, TiB (default 67108864)
-opentelemetry.convertMetricNamesToPrometheus
Whether to convert only metric names into Prometheus-compatible format for the metrics ingested via OpenTelemetry protocol; see https://docs.victoriametrics.com/victoriametrics/integrations/opentelemetry/
-opentelemetry.ignoreResourceAttributes array
Control which resource attributes to ignore, can only be set when 'opentelemetry.promoteAllResourceAttributes' is true.
Supports an array of values separated by comma or specified via multiple flags.
Each array item can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-opentelemetry.labelNameUnderscoreSanitization
Whether to enable prepending of 'key' to labels starting with '_' when -opentelemetry.usePrometheusNaming is enabled. Reserved labels starting with '__' are not modified. See https://docs.victoriametrics.com/victoriametrics/integrations/opentelemetry/ (default true)
-opentelemetry.maxRequestSize size
The maximum size in bytes of a single OpenTelemetry request
Supports the following optional suffixes for size values: KB, MB, GB, TB, KiB, MiB, GiB, TiB (default 67108864)
-opentelemetry.promoteAllResourceAttributes
Whether to promote all resource attributes to labels, except for the ones configured with 'opentelemetry.ignoreResourceAttributes'. (default true)
-opentelemetry.promoteResourceAttributes array
Promote specific list of resource attributes to labels.
Supports an array of values separated by comma or specified via multiple flags.
Each array item can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-opentelemetry.promoteScopeMetadata
Whether to promote OTel scope metadata (i.e. name, version, schema URL, and attributes) to metric labels. (default true)
-opentelemetry.usePrometheusNaming
Whether to convert metric names and labels into Prometheus-compatible format for the metrics ingested via OpenTelemetry protocol; see https://docs.victoriametrics.com/victoriametrics/integrations/opentelemetry/
-opentsdbHTTPListenAddr string
TCP address to listen for OpenTSDB HTTP put requests. Usually :4242 must be set. Doesn't work if empty. See also -opentsdbHTTPListenAddr.useProxyProtocol
-opentsdbHTTPListenAddr.useProxyProtocol
Whether to use proxy protocol for connections accepted at -opentsdbHTTPListenAddr . See https://www.haproxy.org/download/1.8/doc/proxy-protocol.txt
-opentsdbListenAddr string
TCP and UDP address to listen for OpenTSDB metrics. Telnet put messages and HTTP /api/put messages are simultaneously served on TCP port. Usually :4242 must be set. Doesn't work if empty. See also -opentsdbListenAddr.useProxyProtocol
-opentsdbListenAddr.useProxyProtocol
Whether to use proxy protocol for connections accepted at -opentsdbListenAddr . See https://www.haproxy.org/download/1.8/doc/proxy-protocol.txt
-opentsdbTrimTimestamp duration
Trim timestamps for OpenTSDB 'telnet put' data to this duration. Minimum practical duration is 1s. Higher duration (i.e. 1m) may be used for reducing disk space usage for timestamp data (default 1s)
-opentsdbhttp.maxInsertRequestSize size
The maximum size of OpenTSDB HTTP put request
Supports the following optional suffixes for size values: KB, MB, GB, TB, KiB, MiB, GiB, TiB (default 33554432)
-opentsdbhttpTrimTimestamp duration
Trim timestamps for OpenTSDB HTTP data to this duration. Minimum practical duration is 1ms. Higher duration (i.e. 1s) may be used for reducing disk space usage for timestamp data (default 1ms)
-pprofAuthKey value
Auth key for /debug/pprof/* endpoints. It must be passed via authKey query arg. It overrides -httpAuth.*
Flag value can be read from the given file when using -pprofAuthKey=file:///abs/path/to/file or -pprofAuthKey=file://./relative/path/to/file.
Flag value can be read from the given http/https url when using -pprofAuthKey=http://host/path or -pprofAuthKey=https://host/path
-prevCacheRemovalPercent float
Items in the previous caches are removed when the percent of requests it serves becomes lower than this value. Higher values reduce memory usage at the cost of higher CPU usage. See also -cacheExpireDuration (default 0.1)
-pushmetrics.disableCompression
Whether to disable request body compression when pushing metrics to every -pushmetrics.url
-pushmetrics.extraLabel array
Optional labels to add to metrics pushed to every -pushmetrics.url . For example, -pushmetrics.extraLabel='instance="foo"' adds instance="foo" label to all the metrics pushed to every -pushmetrics.url
Supports an array of values separated by comma or specified via multiple flags.
Each array item can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-pushmetrics.header array
Optional HTTP request header to send to every -pushmetrics.url . For example, -pushmetrics.header='Authorization: Basic foobar' adds 'Authorization: Basic foobar' header to every request to every -pushmetrics.url
Supports an array of values separated by comma or specified via multiple flags.
Each array item can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-pushmetrics.interval duration
Interval for pushing metrics to every -pushmetrics.url (default 10s)
-pushmetrics.url array
Optional URL to push metrics exposed at /metrics page. See https://docs.victoriametrics.com/victoriametrics/single-server-victoriametrics/#push-metrics . By default, metrics exposed at /metrics page aren't pushed to any remote storage
Supports an array of values separated by comma or specified via multiple flags.
Each array item can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-relabelConfig string
Optional path to a file with relabeling rules, which are applied to all the ingested metrics. The path can point either to local file or to http url. See https://docs.victoriametrics.com/victoriametrics/single-server-victoriametrics/#relabeling for details. The config is reloaded on SIGHUP signal
-relabelConfigCheckInterval duration
Interval for checking for changes in '-relabelConfig' file. By default the checking is disabled. Send SIGHUP signal in order to force config check for changes
-replicationFactor int
Replication factor for the ingested data, i.e. how many copies to make among distinct -storageNode instances. Note that vmselect must run with -dedup.minScrapeInterval=1ms for data de-duplication when replicationFactor is greater than 1. Higher values for -dedup.minScrapeInterval at vmselect is OK (default 1)
-rpc.disableCompression
Flag is deprecated and kept for backward compatibility, vminsert performs per block compression instead of streaming compression on RPC connection
-rpc.handshakeTimeout duration
Timeout for RPC handshake between vminsert/vmselect and vmstorage. Increase this value if transient handshake failures occur. See https://docs.victoriametrics.com/victoriametrics/troubleshooting/#cluster-instability section for more details. (default 5s)
-secret.flags array
Comma-separated list of flag names with secret values. Values for these flags are hidden in logs and on /metrics page
Supports an array of values separated by comma or specified via multiple flags.
Each array item can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-sortLabels
Whether to sort labels for incoming samples before writing them to storage. This may be needed for reducing memory usage at storage when the order of labels in incoming samples is random. For example, if m{k1="v1",k2="v2"} may be sent as m{k2="v2",k1="v1"}. Enabled sorting for labels can slow down ingestion performance a bit
-storageNode array
Comma-separated addresses of vmstorage nodes; usage: -storageNode=vmstorage-host1,...,vmstorage-hostN . Enterprise version of VictoriaMetrics supports automatic discovery of vmstorage addresses via DNS SRV records. For example, -storageNode=srv+vmstorage.addrs . See https://docs.victoriametrics.com/victoriametrics/cluster-victoriametrics/#automatic-vmstorage-discovery
Supports an array of values separated by comma or specified via multiple flags.
Each array item can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-tls array
Whether to enable TLS for incoming HTTP requests at the given -httpListenAddr (aka https). -tlsCertFile and -tlsKeyFile must be set if -tls is set. See also -mtls
Supports array of values separated by comma or specified via multiple flags.
Empty values are set to false.
-tlsCertFile array
Path to file with TLS certificate for the corresponding -httpListenAddr if -tls is set. Prefer ECDSA certs instead of RSA certs as RSA certs are slower. The provided certificate file is automatically re-read every second, so it can be dynamically updated. See also -tlsAutocertHosts
Supports an array of values separated by comma or specified via multiple flags.
Each array item can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-tlsCipherSuites array
Optional list of TLS cipher suites for incoming requests over HTTPS if -tls is set. See the list of supported cipher suites at https://pkg.go.dev/crypto/tls#pkg-constants
Supports an array of values separated by comma or specified via multiple flags.
Each array item can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-tlsKeyFile array
Path to file with TLS key for the corresponding -httpListenAddr if -tls is set. The provided key file is automatically re-read every second, so it can be dynamically updated. See also -tlsAutocertHosts
Supports an array of values separated by comma or specified via multiple flags.
Each array item can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-tlsMinVersion array
Optional minimum TLS version to use for the corresponding -httpListenAddr if -tls is set. Supported values: TLS10, TLS11, TLS12, TLS13
Supports an array of values separated by comma or specified via multiple flags.
Each array item can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-usePromCompatibleNaming
Whether to replace characters unsupported by Prometheus with underscores in the ingested metric names and label names. For example, foo.bar{a.b='c'} is transformed into foo_bar{a_b='c'} during data ingestion if this flag is set. See https://prometheus.io/docs/concepts/data_model/#metric-names-and-labels
-version
Show VictoriaMetrics version
-vmstorageDialTimeout duration
Timeout for establishing RPC connections from vminsert to vmstorage. See also -vmstorageUserTimeout (default 3s)
-vmstorageUserTimeout duration
Network timeout for RPC connections from vminsert to vmstorage (Linux only). Lower values speed up re-rerouting recovery when some of vmstorage nodes become unavailable because of networking issues. Read more about TCP_USER_TIMEOUT at https://blog.cloudflare.com/when-tcp-sockets-refuse-to-die/ . See also -vmstorageDialTimeout (default 3s)
-zabbixconnector.addDuplicateTagsSeparator string
If set to non-empty value, enables merging of duplicate Zabbix tag values and set a separator for the values of these labels.
-zabbixconnector.addEmptyTagsValue string
If set to non-empty value, enables adding Zabbix tags without values to labels and set value for these labels.
-zabbixconnector.addGroupsValue string
If set to non-empty value, enables adding Zabbix host groups to labels and set value for these labels.
-zabbixconnector.maxLineLen size
The maximum length in bytes of a single line accepted by /zabbixconnector/api/v1/history
Supports the following optional suffixes for size values: KB, MB, GB, TB, KiB, MiB, GiB, TiB (default 33554432)
Enterprise vminsert flags #
These flags are available only in VictoriaMetrics enterprise .
-cluster.tls
Whether to use TLS for connections to -storageNode. See https://docs.victoriametrics.com/victoriametrics/cluster-victoriametrics/#mtls-protection . This flag is available only in VictoriaMetrics enterprise. See https://docs.victoriametrics.com/victoriametrics/enterprise/
-cluster.tlsCAFile string
Path to TLS CA file to use for verifying certificates provided by -storageNode if -cluster.tls flag is set. By default system CA is used. See https://docs.victoriametrics.com/victoriametrics/cluster-victoriametrics/#mtls-protection . This flag is available only in VictoriaMetrics enterprise. See https://docs.victoriametrics.com/victoriametrics/enterprise/
-cluster.tlsCertFile string
Path to client-side TLS certificate file to use when connecting to -storageNode if -cluster.tls flag is set. See https://docs.victoriametrics.com/victoriametrics/cluster-victoriametrics/#mtls-protection . This flag is available only in VictoriaMetrics enterprise. See https://docs.victoriametrics.com/victoriametrics/enterprise/
-cluster.tlsInsecureSkipVerify
Whether to skip verification of TLS certificates provided by -storageNode nodes if -cluster.tls flag is set. Note that disabled TLS certificate verification breaks security. This flag is available only in VictoriaMetrics enterprise. See https://docs.victoriametrics.com/victoriametrics/enterprise/
-cluster.tlsKeyFile string
Path to client-side TLS key file to use when connecting to -storageNode if -cluster.tls flag is set. See https://docs.victoriametrics.com/victoriametrics/cluster-victoriametrics/#mtls-protection . This flag is available only in VictoriaMetrics enterprise. See https://docs.victoriametrics.com/victoriametrics/enterprise/
-clusternative.tls
Whether to use TLS when accepting connections at -clusternativeListenAddr. See https://docs.victoriametrics.com/victoriametrics/cluster-victoriametrics/#mtls-protection . This flag is available only in VictoriaMetrics enterprise. See https://docs.victoriametrics.com/victoriametrics/enterprise/
-clusternative.tlsCAFile string
Path to TLS CA file to use for verifying certificates provided by vminsert, which connects at -clusternativeListenAddr if -clusternative.tls flag is set. By default system CA is used. See https://docs.victoriametrics.com/victoriametrics/cluster-victoriametrics/#mtls-protection . This flag is available only in VictoriaMetrics enterprise. See https://docs.victoriametrics.com/victoriametrics/enterprise/
-clusternative.tlsCertFile string
Path to server-side TLS certificate file to use when accepting connections at -clusternativeListenAddr if -clusternative.tls flag is set. See https://docs.victoriametrics.com/victoriametrics/cluster-victoriametrics/#mtls-protection . This flag is available only in VictoriaMetrics enterprise. See https://docs.victoriametrics.com/victoriametrics/enterprise/
-clusternative.tlsCipherSuites array
Optional list of TLS cipher suites used for connections at -clusternativeListenAddr if -clusternative.tls flag is set. See the list of supported cipher suites at https://pkg.go.dev/crypto/tls#pkg-constants . This flag is available only in VictoriaMetrics enterprise. See https://docs.victoriametrics.com/victoriametrics/enterprise/
Supports an array of values separated by comma or specified via multiple flags.
Each array item can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-clusternative.tlsInsecureSkipVerify
Whether to skip verification of TLS certificates provided by vminsert, which connects to -clusternativeListenAddr if -clusternative.tls flag is set. Note that disabled TLS certificate verification breaks security. This flag is available only in VictoriaMetrics enterprise. See https://docs.victoriametrics.com/victoriametrics/enterprise/
-clusternative.tlsKeyFile string
Path to server-side TLS key file to use when accepting connections at -clusternativeListenAddr if -clusternative.tls flag is set. See https://docs.victoriametrics.com/victoriametrics/cluster-victoriametrics/#mtls-protection . This flag is available only in VictoriaMetrics enterprise. See https://docs.victoriametrics.com/victoriametrics/enterprise/
-eula
Deprecated, please use -license or -licenseFile flags instead. By specifying this flag, you confirm that you have an enterprise license and accept the ESA https://victoriametrics.com/legal/esa/ . This flag is available only in Enterprise binaries. See https://docs.victoriametrics.com/victoriametrics/enterprise/
-license string
License key for VictoriaMetrics Enterprise. See https://victoriametrics.com/products/enterprise/ . Trial Enterprise license can be obtained from https://victoriametrics.com/products/enterprise/trial/ . This flag is available only in Enterprise binaries. The license key can be also passed via file specified by -licenseFile command-line flag
-license.forceOffline
Whether to enable offline verification for VictoriaMetrics Enterprise license key, which has been passed either via -license or via -licenseFile command-line flag. The issued license key must support offline verification feature. Contact info@victoriametrics.com if you need offline license verification. This flag is available only in Enterprise binaries
-licenseFile string
Path to file with license key for VictoriaMetrics Enterprise. See https://victoriametrics.com/products/enterprise/ . Trial Enterprise license can be obtained from https://victoriametrics.com/products/enterprise/trial/ . This flag is available only in Enterprise binaries. The license key can be also passed inline via -license command-line flag
-licenseFile.reloadInterval duration
Interval for reloading the license file specified via -licenseFile. A non-positive value disables periodic and SIGHUP-triggered reloads of -licenseFile. See https://victoriametrics.com/products/enterprise/ . This flag is available only in Enterprise binaries (default 1h0m0s)
-mtls array
Whether to require valid client certificate for https requests to the corresponding -httpListenAddr . This flag works only if -tls flag is set. See also -mtlsCAFile . This flag is available only in Enterprise binaries. See https://docs.victoriametrics.com/victoriametrics/enterprise/
Supports array of values separated by comma or specified via multiple flags.
Empty values are set to false.
-mtlsCAFile array
Optional path to TLS Root CA for verifying client certificates at the corresponding -httpListenAddr when -mtls is enabled. By default the host system TLS Root CA is used for client certificate verification. This flag is available only in Enterprise binaries. See https://docs.victoriametrics.com/victoriametrics/enterprise/
Supports an array of values separated by comma or specified via multiple flags.
Each array item can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-search.denyPartialResponse
Whether to deny partial responses if a part of -storageNode instances fail to perform queries; this trades availability over consistency; see also -search.maxQueryDuration
-storageNode.discoveryInterval duration
Interval for refreshing -storageNode list behind DNS SRV records. The minimum supported interval is 1s. See https://docs.victoriametrics.com/victoriametrics/cluster-victoriametrics/#automatic-vmstorage-discovery . This flag is available only in VictoriaMetrics enterprise. See https://docs.victoriametrics.com/victoriametrics/enterprise/ (default 2s)
-storageNode.filter string
An optional regexp filter for discovered -storageNode addresses according to https://docs.victoriametrics.com/victoriametrics/cluster-victoriametrics/#automatic-vmstorage-discovery. Discovered addresses matching the filter are retained, while other addresses are ignored. This flag is available only in VictoriaMetrics enterprise. See https://docs.victoriametrics.com/victoriametrics/enterprise/
-tlsAutocertCacheDir string
Directory to store TLS certificates issued via Let's Encrypt. Certificates are lost on restarts if this flag isn't set. This flag is available only in Enterprise binaries. See https://docs.victoriametrics.com/victoriametrics/enterprise/
-tlsAutocertEmail string
Contact email for the issued Let's Encrypt TLS certificates. See also -tlsAutocertHosts and -tlsAutocertCacheDir . This flag is available only in Enterprise binaries. See https://docs.victoriametrics.com/victoriametrics/enterprise/
-tlsAutocertHosts array
Optional hostnames for automatic issuing of Let's Encrypt TLS certificates. These hostnames must be reachable at -httpListenAddr . The -httpListenAddr must listen tcp port 443 . The -tlsCertFile and -tlsKeyFile must be unset when -tlsAutocertHosts is used . See also -tlsAutocertEmail and -tlsAutocertCacheDir . This flag is available only in Enterprise binaries. See https://docs.victoriametrics.com/victoriametrics/enterprise/
Supports an array of values separated by comma or specified via multiple flags.
Each array item can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
List of command-line flags for vmselect #
Pass -help to vmselect in order to see the list of supported command-line flags with their description.
Common vmselect flags #
These flags are available in both VictoriaMetrics OSS and VictoriaMetrics Enterprise.
vmselect processes incoming queries by fetching the requested data from vmstorage nodes configured via -storageNode.
See the docs at https://docs.victoriametrics.com/victoriametrics/cluster-victoriametrics/ .
-blockcache.missesBeforeCaching int
The number of cache misses before putting the block into cache. Higher values may reduce indexdb/dataBlocks cache size at the cost of higher CPU and disk read usage (default 2)
-cacheDataPath string
Path to directory for cache files and temporary query results. By default, the cache won't be persisted, and temporary query results will be placed under /tmp/searchResults. If set, the cache will be persisted under cacheDataPath/rollupResult, and temporary query results will be placed under cacheDataPath/tmp/searchResults.
-cacheExpireDuration duration
Items are removed from in-memory caches after they aren't accessed for this duration. Lower values may reduce memory usage at the cost of higher CPU usage. See also -prevCacheRemovalPercent (default 30m0s)
-clusternative.disableCompression
Whether to disable compression of the data sent to vmselect via -clusternativeListenAddr. This reduces CPU usage at the cost of higher network bandwidth usage
-clusternative.maxConcurrentRequests int
The maximum number of concurrent vmselect requests the server can process at -clusternativeListenAddr. Default value depends on the number of available CPU cores. It shouldn't be high, since a single request usually saturates a CPU core at the underlying vmstorage nodes, and many concurrently executed requests may require high amounts of memory. See also -clusternative.maxQueueDuration (default 2*cgroup.AvailableCPUs())
-clusternative.maxQueueDuration duration
The maximum time the incoming query to -clusternativeListenAddr waits for execution when -clusternative.maxConcurrentRequests limit is reached (default 10s)
-clusternative.maxTagKeys int
The maximum number of tag keys returned per search at -clusternativeListenAddr (default 100000)
-clusternative.maxTagValueSuffixesPerSearch int
The maximum number of tag value suffixes returned from /metrics/find at -clusternativeListenAddr (default 100000)
-clusternative.maxTagValues int
The maximum number of tag values returned per search at -clusternativeListenAddr (default 100000)
-clusternativeListenAddr string
TCP address to listen for requests from other vmselect nodes in multi-level cluster setup. See https://docs.victoriametrics.com/victoriametrics/cluster-victoriametrics/#multi-level-cluster-setup . Usually :8401 should be set to match default vmstorage port for vmselect. Disabled work if empty
-dedup.minScrapeInterval duration
Leave only the last sample in every time series per each discrete interval equal to -dedup.minScrapeInterval > 0. See https://docs.victoriametrics.com/victoriametrics/single-server-victoriametrics/#deduplication for details
-deleteAuthKey value
authKey for metrics' deletion via /prometheus/api/v1/admin/tsdb/delete_series and /graphite/tags/delSeries. It could be passed via authKey query arg. It overrides -httpAuth.*
Flag value can be read from the given file when using -deleteAuthKey=file:///abs/path/to/file or -deleteAuthKey=file://./relative/path/to/file.
Flag value can be read from the given http/https url when using -deleteAuthKey=http://host/path or -deleteAuthKey=https://host/path
-denyQueryTracing
Whether to disable the ability to trace queries. See https://docs.victoriametrics.com/victoriametrics/single-server-victoriametrics/#query-tracing
-enableMultitenancyViaHeaders
Enables multitenancy via HTTP headers. See https://docs.victoriametrics.com/victoriametrics/cluster-victoriametrics/#multitenancy-via-headers
-enableTCP6
Whether to enable IPv6 for listening and dialing. By default, only IPv4 TCP and UDP are used
-envflag.enable
Whether to enable reading flags from environment variables in addition to the command line. Command line flag values have priority over values from environment vars. Flags are read only from the command line if this flag isn't set. See https://docs.victoriametrics.com/victoriametrics/single-server-victoriametrics/#environment-variables for more details
-envflag.prefix string
Prefix for environment variables if -envflag.enable is set
-filestream.disableFadvise
Whether to disable fadvise() syscall when reading large data files. The fadvise() syscall prevents from eviction of recently accessed data from OS page cache during background merges and backups. In some rare cases it is better to disable the syscall if it uses too much CPU
-flagsAuthKey value
Auth key for /flags endpoint. It must be passed via authKey query arg. It overrides -httpAuth.*
Flag value can be read from the given file when using -flagsAuthKey=file:///abs/path/to/file or -flagsAuthKey=file://./relative/path/to/file.
Flag value can be read from the given http/https url when using -flagsAuthKey=http://host/path or -flagsAuthKey=https://host/path
-fs.disableMincore
Whether to disable the mincore() syscall for checking mmap()ed files. By default, mincore() is used to detect whether mmap()ed file pages are resident in memory. Disabling mincore() may be needed on older ZFS filesystems (below 2.1.5), since it may trigger ZFS bug. See https://github.com/VictoriaMetrics/VictoriaMetrics/issues/10327 for details.
-fs.disableMmap
Whether to use pread() instead of mmap() for reading data files. By default, mmap() is used for 64-bit arches and pread() is used for 32-bit arches, since they cannot read data files bigger than 2^32 bytes in memory. mmap() is usually faster for reading small data chunks than pread()
-fs.maxConcurrency int
The maximum number of concurrent goroutines to work with files; smaller values may help reducing Go scheduling latency on systems with small number of CPU cores; higher values may help reducing data ingestion latency on systems with high-latency storage such as NFS or Ceph (default fsutil.getDefaultConcurrency())
-globalReplicationFactor int
How many copies of every ingested sample is available across vmstorage groups. vmselect continues returning full responses when up to globalReplicationFactor-1 vmstorage groups are temporarily unavailable. See https://docs.victoriametrics.com/victoriametrics/cluster-victoriametrics/#vmstorage-groups-at-vmselect . See also -replicationFactor (default 1)
-graphite.sanitizeMetricName
Sanitize metric names for the ingested Graphite data. See https://docs.victoriametrics.com/victoriametrics/integrations/graphite/#ingesting
-http.connTimeout duration
Incoming connections to -httpListenAddr are closed after the configured timeout. This may help evenly spreading load among a cluster of services behind TCP-level load balancer. Zero value disables closing of incoming connections (default 2m0s)
-http.disableCORS
Disable CORS for all origins (*)
-http.disableKeepAlive
Whether to disable HTTP keep-alive for incoming connections at -httpListenAddr
-http.disableResponseCompression
Disable compression of HTTP responses to save CPU resources. By default, compression is enabled to save network bandwidth
-http.header.csp string
Value for 'Content-Security-Policy' header, recommended: "default-src 'self'"
-http.header.disableServerHostname
Whether to disable 'X-Server-Hostname' header in HTTP responses
-http.header.frameOptions string
Value for 'X-Frame-Options' header
-http.header.hsts string
Value for 'Strict-Transport-Security' header, recommended: 'max-age=31536000; includeSubDomains'
-http.idleConnTimeout duration
Timeout for incoming idle http connections (default 1m0s)
-http.maxGracefulShutdownDuration duration
The maximum duration for a graceful shutdown of the HTTP server. During this period the server stops accepting new connections, but it will continue serving existing connections. The remaining in-flight requests are canceled before the deadline, so the shutdown can finish within this duration. A highly loaded server may require increased value for a graceful shutdown (default 7s)
-http.pathPrefix string
An optional prefix to add to all the paths handled by http server. For example, if '-http.pathPrefix=/foo/bar' is set, then all the http requests will be handled on '/foo/bar/*' paths. This may be useful for proxied requests. See https://www.robustperception.io/using-external-urls-and-proxies-with-prometheus
-http.shutdownDelay duration
Optional delay before http server shutdown. During this delay, the server returns non-OK responses from /health page, so load balancers can route new requests to other servers
-httpAuth.password value
Password for HTTP server's Basic Auth. The authentication is disabled if -httpAuth.username is empty
Flag value can be read from the given file when using -httpAuth.password=file:///abs/path/to/file or -httpAuth.password=file://./relative/path/to/file.
Flag value can be read from the given http/https url when using -httpAuth.password=http://host/path or -httpAuth.password=https://host/path
-httpAuth.username string
Username for HTTP server's Basic Auth. The authentication is disabled if empty. See also -httpAuth.password
-httpListenAddr array
Address to listen for incoming http requests. See also -httpListenAddr.useProxyProtocol
Supports an array of values separated by comma or specified via multiple flags.
Each array item can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-httpListenAddr.useProxyProtocol array
Whether to use proxy protocol for connections accepted at the given -httpListenAddr . See https://www.haproxy.org/download/1.8/doc/proxy-protocol.txt . With enabled proxy protocol http server cannot serve regular /metrics endpoint. Use -pushmetrics.url for metrics pushing
Supports array of values separated by comma or specified via multiple flags.
Empty values are set to false.
-internStringCacheExpireDuration duration
The expiry duration for caches for interned strings. See https://en.wikipedia.org/wiki/String_interning . See also -internStringMaxLen and -internStringDisableCache (default 6m0s)
-internStringDisableCache
Whether to disable caches for interned strings. This may reduce memory usage at the cost of higher CPU usage. See https://en.wikipedia.org/wiki/String_interning . See also -internStringCacheExpireDuration and -internStringMaxLen
-internStringMaxLen int
The maximum length for strings to intern. A lower limit may save memory at the cost of higher CPU usage. See https://en.wikipedia.org/wiki/String_interning . See also -internStringDisableCache and -internStringCacheExpireDuration (default 500)
-loggerDisableTimestamps
Whether to disable writing timestamps in logs
-loggerErrorsPerSecondLimit int
Per-second limit on the number of ERROR messages. If more than the given number of errors are emitted per second, the remaining errors are suppressed. Zero values disable the rate limit
-loggerFormat string
Format for logs. Possible values: default, json (default "default")
-loggerJSONFields string
Allows renaming fields in JSON formatted logs. Example: "ts:timestamp,msg:message" renames "ts" to "timestamp" and "msg" to "message". Supported fields: ts, level, caller, msg
-loggerLevel string
Minimum level of errors to log. Possible values: INFO, WARN, ERROR, FATAL, PANIC (default "INFO")
-loggerMaxArgLen int
The maximum length of a single logged argument. Longer arguments are replaced with 'arg_start..arg_end', where 'arg_start' and 'arg_end' is prefix and suffix of the arg with the length not exceeding -loggerMaxArgLen / 2 (default 5000)
-loggerOutput string
Output for the logs. Supported values: stderr, stdout (default "stderr")
-loggerTimezone string
Timezone to use for timestamps in logs. Timezone must be a valid IANA Time Zone. For example: America/New_York, Europe/Berlin, Etc/GMT+3 or Local (default "UTC")
-loggerWarnsPerSecondLimit int
Per-second limit on the number of WARN messages. If more than the given number of warns are emitted per second, then the remaining warns are suppressed. Zero values disable the rate limit
-memory.allowedBytes size
Allowed size of system memory VictoriaMetrics caches may occupy. This option overrides -memory.allowedPercent if set to a non-zero value. Too low a value may increase the cache miss rate usually resulting in higher CPU and disk IO usage. Too high a value may evict too much data from the OS page cache resulting in higher disk IO usage. The process may behave unexpectedly if this flag is set too small (e.g., 1 byte).
Supports the following optional suffixes for size values: KB, MB, GB, TB, KiB, MiB, GiB, TiB (default 0)
-memory.allowedPercent float
Allowed percent of system memory VictoriaMetrics caches may occupy. See also -memory.allowedBytes. Too low a value may increase cache miss rate usually resulting in higher CPU and disk IO usage. Too high a value may evict too much data from the OS page cache which will result in higher disk IO usage (default 60)
-metricNamesStatsResetAuthKey value
authKey for resetting metric names usage cache via /api/v1/admin/status/metric_names_stats/reset. It overrides -httpAuth.*. See https://docs.victoriametrics.com/victoriametrics/single-server-victoriametrics/#track-ingested-metrics-usage
Flag value can be read from the given file when using -metricNamesStatsResetAuthKey=file:///abs/path/to/file or -metricNamesStatsResetAuthKey=file://./relative/path/to/file.
Flag value can be read from the given http/https url when using -metricNamesStatsResetAuthKey=http://host/path or -metricNamesStatsResetAuthKey=https://host/path
-metrics.exposeMetadata
Whether to expose TYPE and HELP metadata at the /metrics page, which is exposed at -httpListenAddr . The metadata may be needed when the /metrics page is consumed by systems, which require this information. For example, Managed Prometheus in Google Cloud - https://cloud.google.com/stackdriver/docs/managed-prometheus/troubleshooting#missing-metric-type
-metricsAuthKey value
Auth key for /metrics endpoint. It must be passed via authKey query arg. It overrides -httpAuth.*
Flag value can be read from the given file when using -metricsAuthKey=file:///abs/path/to/file or -metricsAuthKey=file://./relative/path/to/file.
Flag value can be read from the given http/https url when using -metricsAuthKey=http://host/path or -metricsAuthKey=https://host/path
-pprofAuthKey value
Auth key for /debug/pprof/* endpoints. It must be passed via authKey query arg. It overrides -httpAuth.*
Flag value can be read from the given file when using -pprofAuthKey=file:///abs/path/to/file or -pprofAuthKey=file://./relative/path/to/file.
Flag value can be read from the given http/https url when using -pprofAuthKey=http://host/path or -pprofAuthKey=https://host/path
-prevCacheRemovalPercent float
Items in the previous caches are removed when the percent of requests it serves becomes lower than this value. Higher values reduce memory usage at the cost of higher CPU usage. See also -cacheExpireDuration (default 0.1)
-pushmetrics.disableCompression
Whether to disable request body compression when pushing metrics to every -pushmetrics.url
-pushmetrics.extraLabel array
Optional labels to add to metrics pushed to every -pushmetrics.url . For example, -pushmetrics.extraLabel='instance="foo"' adds instance="foo" label to all the metrics pushed to every -pushmetrics.url
Supports an array of values separated by comma or specified via multiple flags.
Each array item can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-pushmetrics.header array
Optional HTTP request header to send to every -pushmetrics.url . For example, -pushmetrics.header='Authorization: Basic foobar' adds 'Authorization: Basic foobar' header to every request to every -pushmetrics.url
Supports an array of values separated by comma or specified via multiple flags.
Each array item can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-pushmetrics.interval duration
Interval for pushing metrics to every -pushmetrics.url (default 10s)
-pushmetrics.url array
Optional URL to push metrics exposed at /metrics page. See https://docs.victoriametrics.com/victoriametrics/single-server-victoriametrics/#push-metrics . By default, metrics exposed at /metrics page aren't pushed to any remote storage
Supports an array of values separated by comma or specified via multiple flags.
Each array item can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-replicationFactor array
How many copies of every ingested sample is available across -storageNode nodes. vmselect continues returning full responses when up to replicationFactor-1 vmstorage nodes are temporarily unavailable. See also -globalReplicationFactor and -search.skipSlowReplicas (default 1)
Supports an array of `key:value` entries separated by comma or specified via multiple flags.
-rpc.handshakeTimeout duration
Timeout for RPC handshake between vminsert/vmselect and vmstorage. Increase this value if transient handshake failures occur. See https://docs.victoriametrics.com/victoriametrics/troubleshooting/#cluster-instability section for more details. (default 5s)
-search.cacheTimestampOffset duration
The maximum duration since the current time for response data, which is always queried from the original raw data, without using the response cache. Increase this value if you see gaps in responses due to time synchronization issues between VictoriaMetrics and data sources (default 5m0s)
-search.denyPartialResponse
Whether to deny partial responses if a part of -storageNode instances fail to perform queries; this trades availability over consistency; see also -search.maxQueryDuration
-search.disableCache
Whether to disable response caching. This may be useful when ingesting historical data. See https://docs.victoriametrics.com/victoriametrics/single-server-victoriametrics/#backfilling . See also -search.resetRollupResultCacheOnStartup
-search.disableImplicitConversion
Whether to return an error for queries that rely on implicit subquery conversions, see https://docs.victoriametrics.com/victoriametrics/metricsql/#subqueries for details. See also -search.logImplicitConversion.
-search.graphiteMaxPointsPerSeries int
The maximum number of points per series Graphite render API can return (default 1000000)
-search.graphiteStorageStep duration
The interval between datapoints stored in the database. It is used at Graphite Render API handler for normalizing the interval between datapoints in case it isn't normalized. It can be overridden by sending 'storage_step' query arg to /render API or by sending the desired interval via 'Storage-Step' http header during querying /render API (default 10s)
-search.ignoreExtraFiltersAtLabelsAPI
Whether to ignore match[], extra_filters[] and extra_label query args at /api/v1/labels and /api/v1/label/.../values . This may be useful for decreasing load on VictoriaMetrics when extra filters match too many time series. The downside is that superfluous labels or series could be returned, which do not match the extra filters. See also -search.maxLabelsAPISeries and -search.maxLabelsAPIDuration
-search.inmemoryBufSizeBytes size
Size for in-memory data blocks used during processing search requests. By default, the size is automatically calculated based on available memory. Adjust this flag value if you observe that vm_tmp_blocks_max_inmemory_file_size_bytes metric constantly shows much higher values than vm_tmp_blocks_inmemory_file_size_bytes. See https://github.com/VictoriaMetrics/VictoriaMetrics/pull/6851
Supports the following optional suffixes for size values: KB, MB, GB, TB, KiB, MiB, GiB, TiB (default 0)
-search.latencyOffset duration
The time when data points become visible in query results after the collection. It can be overridden on per-query basis via latency_offset arg. Too small value can result in incomplete last points for query results (default 30s)
-search.logImplicitConversion
Whether to log queries with implicit subquery conversions, see https://docs.victoriametrics.com/victoriametrics/metricsql/#subqueries for details. Such conversion can be disabled using -search.disableImplicitConversion.
-search.logQueryMemoryUsage size
Log query and increment vm_memory_intensive_queries_total metric each time the query requires more memory than specified by this flag. This may help detecting and optimizing heavy queries. Query logging is disabled by default. See also -search.logSlowQueryDuration and -search.maxMemoryPerQuery
Supports the following optional suffixes for size values: KB, MB, GB, TB, KiB, MiB, GiB, TiB (default 0)
-search.logSlowQueryDuration duration
Log queries with execution time exceeding this value. Zero disables slow query logging. See also -search.logQueryMemoryUsage (default 5s)
-search.maxBinaryOpPushdownLabelValues int
The maximum number of values for a label in the first expression that can be extracted as a common label filter and pushed down to the second expression in a binary operation. A larger value makes the pushed-down filter more complex but fewer time series will be returned. This flag is useful when selective label (e.g., 'instance') contains numerous values, and storage resources are abundant. (default 100)
-search.maxConcurrentRequests int
The maximum number of concurrent search requests. It shouldn't be high, since a single request can saturate all the CPU cores, while many concurrently executed requests may require high amounts of memory. See also -search.maxQueueDuration and -search.maxMemoryPerQuery (default vmselect.getDefaultMaxConcurrentRequests())
-search.maxDeleteDuration duration
The maximum duration for /api/v1/admin/tsdb/delete_series call (default 5m0s)
-search.maxDeleteSeries int
The maximum number of time series, which can be deleted using /api/v1/admin/tsdb/delete_series. This option allows limiting memory usage (default 1000000)
-search.maxExportDuration duration
The maximum duration for /api/v1/export call (default 720h0m0s)
-search.maxExportSeries int
The maximum number of time series, which can be returned from /api/v1/export* APIs. This option allows limiting memory usage (default 10000000)
-search.maxFederateSeries int
The maximum number of time series, which can be returned from /federate. This option allows limiting memory usage (default 1000000)
-search.maxGraphitePathExpressionLen int
The maximum length of pathExpression field in Graphite series. Longer expressions are truncated to prevent memory exhaustion on complex nested queries. Set to 0 to disable truncation. (default 1024)
-search.maxGraphiteSeries int
The maximum number of time series, which can be scanned during queries to Graphite Render API. See https://docs.victoriametrics.com/victoriametrics/integrations/graphite/#render-api (default 300000)
-search.maxGraphiteTagKeys int
The maximum number of tag keys returned from Graphite API, which returns tags. See https://docs.victoriametrics.com/victoriametrics/integrations/graphite/#tags-api (default 100000)
-search.maxGraphiteTagValues int
The maximum number of tag values returned from Graphite API, which returns tag values. See https://docs.victoriametrics.com/victoriametrics/integrations/graphite/#tags-api (default 100000)
-search.maxLabelsAPIDuration duration
The maximum duration for /api/v1/labels, /api/v1/label/.../values and /api/v1/series requests. See also -search.maxLabelsAPISeries and -search.ignoreExtraFiltersAtLabelsAPI (default 5s)
-search.maxLabelsAPISeries int
The maximum number of time series, which could be scanned when searching for the matching time series at /api/v1/labels and /api/v1/label/.../values. This option allows limiting memory usage and CPU usage. See also -search.maxLabelsAPIDuration, -search.maxTagKeys, -search.maxTagValues and -search.ignoreExtraFiltersAtLabelsAPI (default 1000000)
-search.maxLookback duration
Synonym to -query.lookback-delta from Prometheus. The value is dynamically detected from interval between time series datapoints if not set. It can be overridden on per-query basis via max_lookback arg. See also '-search.maxStalenessInterval' flag, which has the same meaning due to historical reasons
-search.maxMemoryPerQuery size
The maximum amounts of memory a single query may consume. Queries requiring more memory are rejected. The total memory limit for concurrently executed queries can be estimated as -search.maxMemoryPerQuery multiplied by -search.maxConcurrentRequests . See also -search.logQueryMemoryUsage
Supports the following optional suffixes for size values: KB, MB, GB, TB, KiB, MiB, GiB, TiB (default 0)
-search.maxPointsPerTimeseries int
The maximum points per a single timeseries returned from /api/v1/query_range. This option doesn't limit the number of scanned raw samples in the database. The main purpose of this option is to limit the number of per-series points returned to graphing UI such as VMUI or Grafana. There is no sense in setting this limit to values bigger than the horizontal resolution of the graph. See also -search.maxResponseSeries (default 30000)
-search.maxPointsSubqueryPerTimeseries int
The maximum number of points per series, which can be generated by subquery. See https://valyala.medium.com/prometheus-subqueries-in-victoriametrics-9b1492b720b3 (default 100000)
-search.maxQueryDuration duration
The maximum duration for query execution. It can be overridden to a smaller value on a per-query basis via 'timeout' query arg (default 30s)
-search.maxQueryLen size
The maximum search query length in bytes
Supports the following optional suffixes for size values: KB, MB, GB, TB, KiB, MiB, GiB, TiB (default 16384)
-search.maxQueueDuration duration
The maximum time the request waits for execution when -search.maxConcurrentRequests limit is reached; see also -search.maxQueryDuration (default 10s)
-search.maxResponseSeries int
The maximum number of time series which can be returned from /api/v1/query and /api/v1/query_range . The limit is disabled if it equals to 0. See also -search.maxPointsPerTimeseries and -search.maxUniqueTimeseries
-search.maxSamplesPerQuery int
The maximum number of raw samples a single query can process across all time series. This protects from heavy queries, which select unexpectedly high number of raw samples. See also -search.maxSamplesPerSeries (default 1000000000)
-search.maxSamplesPerSeries int
The maximum number of raw samples a single query can scan per each time series. See also -search.maxSamplesPerQuery (default 30000000)
-search.maxSeries int
The maximum number of time series, which can be returned from /api/v1/series. This option allows limiting memory usage (default 30000)
-search.maxSeriesPerAggrFunc int
The maximum number of time series an aggregate MetricsQL function can generate (default 1000000)
-search.maxStalenessInterval duration
The maximum interval for staleness calculations. By default, it is automatically calculated from the median interval between samples. This flag could be useful for tuning Prometheus data model closer to Influx-style data model. See https://prometheus.io/docs/prometheus/latest/querying/basics/#staleness for details. See also '-search.setLookbackToStep' flag
-search.maxStatusRequestDuration duration
The maximum duration for /api/v1/status/* requests (default 5m0s)
-search.maxStepForPointsAdjustment duration
The maximum step when /api/v1/query_range handler adjusts points with timestamps closer than -search.latencyOffset to the current time. The adjustment is needed because such points may contain incomplete data (default 1m0s)
-search.maxTSDBStatusSeries int
The maximum number of time series, which can be processed during the call to /api/v1/status/tsdb. This option allows limiting memory usage (default 10000000)
-search.maxTSDBStatusTopNSeries int
The maximum value of 'topN' argument that can be passed to /api/v1/status/tsdb API. This option allows limiting memory usage. See https://docs.victoriametrics.com/victoriametrics/single-server-victoriametrics/#tsdb-stats (default 1000)
-search.maxTagValueSuffixesPerSearch int
The maximum number of tag value suffixes returned from /metrics/find (default 100000)
-search.maxUniqueTimeseries -search.maxUniqueTimeseries
The maximum number of unique time series, which can be selected during /api/v1/query and /api/v1/query_range queries. This option allows limiting memory usage. The limit can't exceed the explicitly set corresponding value -search.maxUniqueTimeseries on vmstorage side.
-search.maxWorkersPerQuery int
The maximum number of CPU cores a single query can use. The default value should work good for most cases. The flag can be set to lower values for improving performance of big number of concurrently executed queries. The flag can be set to bigger values for improving performance of heavy queries, which scan big number of time series (>10K) and/or big number of samples (>100M). There is no sense in setting this flag to values bigger than the number of CPU cores available on the system (default netstorage.defaultMaxWorkersPerQuery())
-search.minStalenessInterval duration
The minimum interval for staleness calculations. This flag could be useful for removing gaps on graphs generated from time series with irregular intervals between samples. See also '-search.maxStalenessInterval'
-search.minWindowForInstantRollupOptimization duration
Enable cache-based optimization for repeated queries to /api/v1/query (aka instant queries), which contain rollup functions with lookbehind window exceeding the given value (default 3h0m0s)
-search.noStaleMarkers
Set this flag to true if the database doesn't contain Prometheus stale markers, so there is no need in spending additional CPU time on its handling. Staleness markers may exist only in data obtained from Prometheus scrape targets
-search.queryStats.lastQueriesCount int
Query stats for /api/v1/status/top_queries is tracked on this number of last queries. Zero value disables query stats tracking (default 20000)
-search.queryStats.minQueryDuration duration
The minimum duration for queries to track in query stats at /api/v1/status/top_queries. Queries with lower duration are ignored in query stats (default 1ms)
-search.queryStats.minQueryMemoryUsage size
The minimum memory bytes consumption for queries to track in query stats at /api/v1/status/top_queries. Queries with lower memory bytes consumption are ignored in query stats
Supports the following optional suffixes for size values: KB, MB, GB, TB, KiB, MiB, GiB, TiB (default 1024)
-search.resetCacheAuthKey value
Optional authKey for resetting rollup cache via /internal/resetRollupResultCache call. It could be passed via authKey query arg. It overrides -httpAuth.*. It'll be used when reset request is propagate to other -selectNode.
Flag value can be read from the given file when using -search.resetCacheAuthKey=file:///abs/path/to/file or -search.resetCacheAuthKey=file://./relative/path/to/file.
Flag value can be read from the given http/https url when using -search.resetCacheAuthKey=http://host/path or -search.resetCacheAuthKey=https://host/path
-search.resetRollupResultCacheOnStartup
Whether to reset rollup result cache on startup. See https://docs.victoriametrics.com/victoriametrics/single-server-victoriametrics/#rollup-result-cache . See also -search.disableCache
-search.setLookbackToStep
Whether to fix lookback interval to 'step' query arg value. If set to true, the query model becomes closer to InfluxDB data model. If set to true, then -search.maxLookback and -search.maxStalenessInterval are ignored
-search.skipSlowReplicas
Whether to skip -replicationFactor - 1 slowest vmstorage nodes during querying. Enabling this setting may improve query speed, but it could also lead to incomplete results if some queried data has less than -replicationFactor copies at vmstorage nodes. Consider enabling this setting only if all the queried data contains -replicationFactor copies in the cluster
-search.tenantCacheExpireDuration duration
Expiry duration for caching tenants in memory. A zero value disables caching, causing tenants to be fetched from storage nodes on every query. (default 5m0s)
-search.treatDotsAsIsInRegexps
Whether to treat dots as is in regexp label filters used in queries. For example, foo{bar=~"a.b.c"} will be automatically converted to foo{bar=~"a\\.b\\.c"}, i.e. all the dots in regexp filters will be automatically escaped in order to match only dot char instead of matching any char. Dots in ".+", ".*" and ".{n}" regexps aren't escaped. This option is DEPRECATED in favor of {__graphite__="a.*.c"} syntax for selecting metrics matching the given Graphite metrics filter
-secret.flags array
Comma-separated list of flag names with secret values. Values for these flags are hidden in logs and on /metrics page
Supports an array of values separated by comma or specified via multiple flags.
Each array item can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-selectNode array
A list of vmselect node addresses to propagate the '/internal/resetRollupResultCache?propagate=1' call. If either this flag or the 'propagate=1' query parameter is missing, the cache must be purged on each vmselect instance individually.Comma-separated addresses of vmselect nodes; usage: -selectNode=vmselect-host1,...,vmselect-hostN
Supports an array of values separated by comma or specified via multiple flags.
Each array item can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-storageNode array
Comma-separated addresses of vmstorage nodes; usage: -storageNode=vmstorage-host1,...,vmstorage-hostN . Enterprise version of VictoriaMetrics supports automatic discovery of vmstorage addresses via DNS SRV records. For example, -storageNode=srv+vmstorage.addrs . See https://docs.victoriametrics.com/victoriametrics/cluster-victoriametrics/#automatic-vmstorage-discovery
Supports an array of values separated by comma or specified via multiple flags.
Each array item can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-tls array
Whether to enable TLS for incoming HTTP requests at the given -httpListenAddr (aka https). -tlsCertFile and -tlsKeyFile must be set if -tls is set. See also -mtls
Supports array of values separated by comma or specified via multiple flags.
Empty values are set to false.
-tlsCertFile array
Path to file with TLS certificate for the corresponding -httpListenAddr if -tls is set. Prefer ECDSA certs instead of RSA certs as RSA certs are slower. The provided certificate file is automatically re-read every second, so it can be dynamically updated. See also -tlsAutocertHosts
Supports an array of values separated by comma or specified via multiple flags.
Each array item can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-tlsCipherSuites array
Optional list of TLS cipher suites for incoming requests over HTTPS if -tls is set. See the list of supported cipher suites at https://pkg.go.dev/crypto/tls#pkg-constants
Supports an array of values separated by comma or specified via multiple flags.
Each array item can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-tlsKeyFile array
Path to file with TLS key for the corresponding -httpListenAddr if -tls is set. The provided key file is automatically re-read every second, so it can be dynamically updated. See also -tlsAutocertHosts
Supports an array of values separated by comma or specified via multiple flags.
Each array item can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-tlsMinVersion array
Optional minimum TLS version to use for the corresponding -httpListenAddr if -tls is set. Supported values: TLS10, TLS11, TLS12, TLS13
Supports an array of values separated by comma or specified via multiple flags.
Each array item can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-version
Show VictoriaMetrics version
-vmalert.proxyURL string
Optional URL for proxying requests to vmalert. For example, if -vmalert.proxyURL=http://vmalert:8880 , then alerting API requests such as /api/v1/rules from Grafana will be proxied to http://vmalert:8880/api/v1/rules . See https://docs.victoriametrics.com/victoriametrics/cluster-victoriametrics/#vmalert
-vmstorageDialTimeout duration
Timeout for establishing RPC connections from vmselect to vmstorage. See also -vmstorageUserTimeout (default 3s)
-vmstorageUserTimeout duration
Network timeout for RPC connections from vmselect to vmstorage (Linux only). Lower values reduce the maximum query durations when some vmstorage nodes become unavailable because of networking issues. Read more about TCP_USER_TIMEOUT at https://blog.cloudflare.com/when-tcp-sockets-refuse-to-die/ . See also -vmstorageDialTimeout (default 3s)
-vmui.customDashboardsPath string
Optional path to vmui dashboards. See https://github.com/VictoriaMetrics/VictoriaMetrics/tree/master/app/vmui/packages/vmui/public/dashboards
-vmui.defaultTimezone string
The default timezone to be used in vmui. Timezone must be a valid IANA Time Zone. For example: America/New_York, Europe/Berlin, Etc/GMT+3 or Local
Enterprise vmselect flags #
These flags are available only in VictoriaMetrics enterprise .
-cluster.tls
Whether to use TLS for connections to -storageNode. See https://docs.victoriametrics.com/victoriametrics/cluster-victoriametrics/#mtls-protection . This flag is available only in VictoriaMetrics enterprise. See https://docs.victoriametrics.com/victoriametrics/enterprise/
-cluster.tlsCAFile string
Path to TLS CA file to use for verifying certificates provided by -storageNode if -cluster.tls flag is set. By default system CA is used. See https://docs.victoriametrics.com/victoriametrics/cluster-victoriametrics/#mtls-protection . This flag is available only in VictoriaMetrics enterprise. See https://docs.victoriametrics.com/victoriametrics/enterprise/
-cluster.tlsCertFile string
Path to client-side TLS certificate file to use when connecting to -storageNode if -cluster.tls flag is set. See https://docs.victoriametrics.com/victoriametrics/cluster-victoriametrics/#mtls-protection . This flag is available only in VictoriaMetrics enterprise. See https://docs.victoriametrics.com/victoriametrics/enterprise/
-cluster.tlsInsecureSkipVerify
Whether to skip verification of TLS certificates provided by -storageNode nodes if -cluster.tls flag is set. Note that disabled TLS certificate verification breaks security. This flag is available only in VictoriaMetrics enterprise. See https://docs.victoriametrics.com/victoriametrics/enterprise/
-cluster.tlsKeyFile string
Path to client-side TLS key file to use when connecting to -storageNode if -cluster.tls flag is set. See https://docs.victoriametrics.com/victoriametrics/cluster-victoriametrics/#mtls-protection . This flag is available only in VictoriaMetrics enterprise. See https://docs.victoriametrics.com/victoriametrics/enterprise/
-clusternative.tls
Whether to use TLS when accepting connections at -clusternativeListenAddr. See https://docs.victoriametrics.com/victoriametrics/cluster-victoriametrics/#mtls-protection . This flag is available only in VictoriaMetrics enterprise. See https://docs.victoriametrics.com/victoriametrics/enterprise/
-clusternative.tlsCAFile string
Path to TLS CA file to use for verifying certificates provided by vmselect, which connects at -clusternativeListenAddr if -clusternative.tls flag is set. By default system CA is used. See https://docs.victoriametrics.com/victoriametrics/cluster-victoriametrics/#mtls-protection . This flag is available only in VictoriaMetrics enterprise. See https://docs.victoriametrics.com/victoriametrics/enterprise/
-clusternative.tlsCertFile string
Path to server-side TLS certificate file to use when accepting connections at -clusternativeListenAddr if -clusternative.tls flag is set. See https://docs.victoriametrics.com/victoriametrics/cluster-victoriametrics/#mtls-protection . This flag is available only in VictoriaMetrics enterprise. See https://docs.victoriametrics.com/victoriametrics/enterprise/
-clusternative.tlsCipherSuites array
Optional list of TLS cipher suites used for connections at -clusternativeListenAddr if -clusternative.tls flag is set. See the list of supported cipher suites at https://pkg.go.dev/crypto/tls#pkg-constants . This flag is available only in VictoriaMetrics enterprise. See https://docs.victoriametrics.com/victoriametrics/enterprise/
Supports an array of values separated by comma or specified via multiple flags.
Each array item can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-clusternative.tlsInsecureSkipVerify
Whether to skip verification of TLS certificates provided by vmselect, which connects to -clusternativeListenAddr if -clusternative.tls flag is set. Note that disabled TLS certificate verification breaks security. This flag is available only in VictoriaMetrics enterprise. See https://docs.victoriametrics.com/victoriametrics/enterprise/
-clusternative.tlsKeyFile string
Path to server-side TLS key file to use when accepting connections at -clusternativeListenAddr if -clusternative.tls flag is set. See https://docs.victoriametrics.com/victoriametrics/cluster-victoriametrics/#mtls-protection . This flag is available only in VictoriaMetrics enterprise. See https://docs.victoriametrics.com/victoriametrics/enterprise/
-downsampling.period array
Comma-separated downsampling periods in the format 'offset:period'. For example, '30d:10m' instructs to leave a single sample per 10 minutes for samples older than 30 days. When setting multiple downsampling periods, it is necessary for the periods to be multiples of each other. See https://docs.victoriametrics.com/victoriametrics/single-server-victoriametrics/#downsampling for details. This flag is available only in VictoriaMetrics enterprise. See https://docs.victoriametrics.com/victoriametrics/enterprise/
Supports an array of values separated by comma or specified via multiple flags.
Each array item can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-eula
Deprecated, please use -license or -licenseFile flags instead. By specifying this flag, you confirm that you have an enterprise license and accept the ESA https://victoriametrics.com/legal/esa/ . This flag is available only in Enterprise binaries. See https://docs.victoriametrics.com/victoriametrics/enterprise/
-license string
License key for VictoriaMetrics Enterprise. See https://victoriametrics.com/products/enterprise/ . Trial Enterprise license can be obtained from https://victoriametrics.com/products/enterprise/trial/ . This flag is available only in Enterprise binaries. The license key can be also passed via file specified by -licenseFile command-line flag
-license.forceOffline
Whether to enable offline verification for VictoriaMetrics Enterprise license key, which has been passed either via -license or via -licenseFile command-line flag. The issued license key must support offline verification feature. Contact info@victoriametrics.com if you need offline license verification. This flag is available only in Enterprise binaries
-licenseFile string
Path to file with license key for VictoriaMetrics Enterprise. See https://victoriametrics.com/products/enterprise/ . Trial Enterprise license can be obtained from https://victoriametrics.com/products/enterprise/trial/ . This flag is available only in Enterprise binaries. The license key can be also passed inline via -license command-line flag
-licenseFile.reloadInterval duration
Interval for reloading the license file specified via -licenseFile. A non-positive value disables periodic and SIGHUP-triggered reloads of -licenseFile. See https://victoriametrics.com/products/enterprise/ . This flag is available only in Enterprise binaries (default 1h0m0s)
-mtls array
Whether to require valid client certificate for https requests to the corresponding -httpListenAddr . This flag works only if -tls flag is set. See also -mtlsCAFile . This flag is available only in Enterprise binaries. See https://docs.victoriametrics.com/victoriametrics/enterprise/
Supports array of values separated by comma or specified via multiple flags.
Empty values are set to false.
-mtlsCAFile array
Optional path to TLS Root CA for verifying client certificates at the corresponding -httpListenAddr when -mtls is enabled. By default the host system TLS Root CA is used for client certificate verification. This flag is available only in Enterprise binaries. See https://docs.victoriametrics.com/victoriametrics/enterprise/
Supports an array of values separated by comma or specified via multiple flags.
Each array item can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-search.logSlowQueryStats duration
Log query statistics if execution time exceeding this value - see https://docs.victoriametrics.com/victoriametrics/query-stats . Zero disables slow query statistics logging. This flag is available only in VictoriaMetrics enterprise. See https://docs.victoriametrics.com/victoriametrics/enterprise/ (default 5s)
-search.logSlowQueryStatsHeaders array
HTTP request header keys to log for queries exceeding the threshold set by -search.logSlowQueryStats. Case-insensitive. By default, no headers are logged. This flag is available only in VictoriaMetrics enterprise. See https://docs.victoriametrics.com/victoriametrics/query-stats/#log-fields for details and examples.
Supports an array of values separated by comma or specified via multiple flags.
Each array item can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-storageNode.discoveryInterval duration
Interval for refreshing -storageNode list behind DNS SRV records. The minimum supported interval is 1s. See https://docs.victoriametrics.com/victoriametrics/cluster-victoriametrics/#automatic-vmstorage-discovery . This flag is available only in VictoriaMetrics enterprise. See https://docs.victoriametrics.com/victoriametrics/enterprise/ (default 2s)
-storageNode.filter string
An optional regexp filter for discovered -storageNode addresses according to https://docs.victoriametrics.com/victoriametrics/cluster-victoriametrics/#automatic-vmstorage-discovery. Discovered addresses matching the filter are retained, while other addresses are ignored. This flag is available only in VictoriaMetrics enterprise. See https://docs.victoriametrics.com/victoriametrics/enterprise/
-tlsAutocertCacheDir string
Directory to store TLS certificates issued via Let's Encrypt. Certificates are lost on restarts if this flag isn't set. This flag is available only in Enterprise binaries. See https://docs.victoriametrics.com/victoriametrics/enterprise/
-tlsAutocertEmail string
Contact email for the issued Let's Encrypt TLS certificates. See also -tlsAutocertHosts and -tlsAutocertCacheDir . This flag is available only in Enterprise binaries. See https://docs.victoriametrics.com/victoriametrics/enterprise/
-tlsAutocertHosts array
Optional hostnames for automatic issuing of Let's Encrypt TLS certificates. These hostnames must be reachable at -httpListenAddr . The -httpListenAddr must listen tcp port 443 . The -tlsCertFile and -tlsKeyFile must be unset when -tlsAutocertHosts is used . See also -tlsAutocertEmail and -tlsAutocertCacheDir . This flag is available only in Enterprise binaries. See https://docs.victoriametrics.com/victoriametrics/enterprise/
Supports an array of values separated by comma or specified via multiple flags.
Each array item can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
List of command-line flags for vmstorage #
Pass -help to vmstorage in order to see the list of supported command-line flags with their description.
Common vmstorage flags #
These flags are available in both VictoriaMetrics OSS and VictoriaMetrics Enterprise.
vmstorage stores time series data obtained from vminsert and returns the requested data to vmselect.
See the docs at https://docs.victoriametrics.com/victoriametrics/cluster-victoriametrics/ .
-bigMergeConcurrency int
Deprecated: this flag does nothing
-blockcache.missesBeforeCaching int
The number of cache misses before putting the block into cache. Higher values may reduce indexdb/dataBlocks cache size at the cost of higher CPU and disk read usage (default 2)
-cacheExpireDuration duration
Items are removed from in-memory caches after they aren't accessed for this duration. Lower values may reduce memory usage at the cost of higher CPU usage. See also -prevCacheRemovalPercent (default 30m0s)
-dedup.minScrapeInterval duration
Leave only the last sample in every time series per each discrete interval equal to -dedup.minScrapeInterval > 0. See also -streamAggr.dedupInterval and https://docs.victoriametrics.com/victoriametrics/single-server-victoriametrics/#deduplication
-denyQueriesOutsideRetention
Whether to deny queries outside the configured -retentionPeriod and -futureRetention. When set, then /api/v1/query_range will return an error for queries with 'from' value outside -retentionPeriod or 'to' value beyond -futureRetention. This may be useful when multiple data sources with distinct retentions are hidden behind query-tee
-denyQueryTracing
Whether to disable the ability to trace queries. See https://docs.victoriametrics.com/victoriametrics/single-server-victoriametrics/#query-tracing
-disablePerDayIndex
Disable per-day index and use global index for all searches. This may improve performance and decrease disk space usage for the use cases with fixed set of timeseries scattered across a big time range (for example, when loading years of historical data). See https://docs.victoriametrics.com/victoriametrics/single-server-victoriametrics/#index-tuning
-enableTCP6
Whether to enable IPv6 for listening and dialing. By default, only IPv4 TCP and UDP are used
-envflag.enable
Whether to enable reading flags from environment variables in addition to the command line. Command line flag values have priority over values from environment vars. Flags are read only from the command line if this flag isn't set. See https://docs.victoriametrics.com/victoriametrics/single-server-victoriametrics/#environment-variables for more details
-envflag.prefix string
Prefix for environment variables if -envflag.enable is set
-filestream.disableFadvise
Whether to disable fadvise() syscall when reading large data files. The fadvise() syscall prevents from eviction of recently accessed data from OS page cache during background merges and backups. In some rare cases it is better to disable the syscall if it uses too much CPU
-finalMergeDelay duration
Deprecated: this flag does nothing
-flagsAuthKey value
Auth key for /flags endpoint. It must be passed via authKey query arg. It overrides -httpAuth.*
Flag value can be read from the given file when using -flagsAuthKey=file:///abs/path/to/file or -flagsAuthKey=file://./relative/path/to/file.
Flag value can be read from the given http/https url when using -flagsAuthKey=http://host/path or -flagsAuthKey=https://host/path
-forceFlushAuthKey value
authKey, which must be passed in query string to /internal/force_flush pages. It overrides -httpAuth.*
Flag value can be read from the given file when using -forceFlushAuthKey=file:///abs/path/to/file or -forceFlushAuthKey=file://./relative/path/to/file.
Flag value can be read from the given http/https url when using -forceFlushAuthKey=http://host/path or -forceFlushAuthKey=https://host/path
-forceMergeAuthKey value
authKey, which must be passed in query string to /internal/force_merge pages. It overrides -httpAuth.*
Flag value can be read from the given file when using -forceMergeAuthKey=file:///abs/path/to/file or -forceMergeAuthKey=file://./relative/path/to/file.
Flag value can be read from the given http/https url when using -forceMergeAuthKey=http://host/path or -forceMergeAuthKey=https://host/path
-fs.disableMincore
Whether to disable the mincore() syscall for checking mmap()ed files. By default, mincore() is used to detect whether mmap()ed file pages are resident in memory. Disabling mincore() may be needed on older ZFS filesystems (below 2.1.5), since it may trigger ZFS bug. See https://github.com/VictoriaMetrics/VictoriaMetrics/issues/10327 for details.
-fs.disableMmap
Whether to use pread() instead of mmap() for reading data files. By default, mmap() is used for 64-bit arches and pread() is used for 32-bit arches, since they cannot read data files bigger than 2^32 bytes in memory. mmap() is usually faster for reading small data chunks than pread()
-fs.maxConcurrency int
The maximum number of concurrent goroutines to work with files; smaller values may help reducing Go scheduling latency on systems with small number of CPU cores; higher values may help reducing data ingestion latency on systems with high-latency storage such as NFS or Ceph (default fsutil.getDefaultConcurrency())
-futureRetention value
Data with timestamps bigger than now+futureRetention is automatically deleted. The minimum futureRetention is 2 days. See https://docs.victoriametrics.com/victoriametrics/single-server-victoriametrics/#retention
The following optional suffixes are supported: s (second), h (hour), d (day), w (week), M (month), y (year). If suffix isn't set, then the duration is counted in months (default 2d)
-http.connTimeout duration
Incoming connections to -httpListenAddr are closed after the configured timeout. This may help evenly spreading load among a cluster of services behind TCP-level load balancer. Zero value disables closing of incoming connections (default 2m0s)
-http.disableCORS
Disable CORS for all origins (*)
-http.disableKeepAlive
Whether to disable HTTP keep-alive for incoming connections at -httpListenAddr
-http.disableResponseCompression
Disable compression of HTTP responses to save CPU resources. By default, compression is enabled to save network bandwidth
-http.header.csp string
Value for 'Content-Security-Policy' header, recommended: "default-src 'self'"
-http.header.disableServerHostname
Whether to disable 'X-Server-Hostname' header in HTTP responses
-http.header.frameOptions string
Value for 'X-Frame-Options' header
-http.header.hsts string
Value for 'Strict-Transport-Security' header, recommended: 'max-age=31536000; includeSubDomains'
-http.idleConnTimeout duration
Timeout for incoming idle http connections (default 1m0s)
-http.maxGracefulShutdownDuration duration
The maximum duration for a graceful shutdown of the HTTP server. During this period the server stops accepting new connections, but it will continue serving existing connections. The remaining in-flight requests are canceled before the deadline, so the shutdown can finish within this duration. A highly loaded server may require increased value for a graceful shutdown (default 7s)
-http.pathPrefix string
An optional prefix to add to all the paths handled by http server. For example, if '-http.pathPrefix=/foo/bar' is set, then all the http requests will be handled on '/foo/bar/*' paths. This may be useful for proxied requests. See https://www.robustperception.io/using-external-urls-and-proxies-with-prometheus
-http.shutdownDelay duration
Optional delay before http server shutdown. During this delay, the server returns non-OK responses from /health page, so load balancers can route new requests to other servers
-httpAuth.password value
Password for HTTP server's Basic Auth. The authentication is disabled if -httpAuth.username is empty
Flag value can be read from the given file when using -httpAuth.password=file:///abs/path/to/file or -httpAuth.password=file://./relative/path/to/file.
Flag value can be read from the given http/https url when using -httpAuth.password=http://host/path or -httpAuth.password=https://host/path
-httpAuth.username string
Username for HTTP server's Basic Auth. The authentication is disabled if empty. See also -httpAuth.password
-httpListenAddr array
Address to listen for incoming http requests. See also -httpListenAddr.useProxyProtocol
Supports an array of values separated by comma or specified via multiple flags.
Each array item can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-httpListenAddr.useProxyProtocol array
Whether to use proxy protocol for connections accepted at the given -httpListenAddr . See https://www.haproxy.org/download/1.8/doc/proxy-protocol.txt . With enabled proxy protocol http server cannot serve regular /metrics endpoint. Use -pushmetrics.url for metrics pushing
Supports array of values separated by comma or specified via multiple flags.
Empty values are set to false.
-inmemoryDataFlushInterval duration
The interval for guaranteed saving of in-memory data to disk. The saved data survives unclean shutdowns such as OOM crash, hardware reset, SIGKILL, etc. Bigger intervals may help increase the lifetime of flash storage with limited write cycles (e.g. Raspberry PI). Smaller intervals increase disk IO load. Minimum supported value is 1s (default 5s)
-insert.maxQueueDuration duration
The maximum duration to wait in the queue when -maxConcurrentInserts concurrent insert requests are executed (default 1m0s)
-internStringCacheExpireDuration duration
The expiry duration for caches for interned strings. See https://en.wikipedia.org/wiki/String_interning . See also -internStringMaxLen and -internStringDisableCache (default 6m0s)
-internStringDisableCache
Whether to disable caches for interned strings. This may reduce memory usage at the cost of higher CPU usage. See https://en.wikipedia.org/wiki/String_interning . See also -internStringCacheExpireDuration and -internStringMaxLen
-internStringMaxLen int
The maximum length for strings to intern. A lower limit may save memory at the cost of higher CPU usage. See https://en.wikipedia.org/wiki/String_interning . See also -internStringDisableCache and -internStringCacheExpireDuration (default 500)
-logNewSeries
Whether to log new series. This option is for debug purposes only. It can lead to performance issues when big number of new series are ingested into VictoriaMetrics
-logNewSeriesAuthKey value
authKey, which must be passed in query string to /internal/log_new_series. It overrides -httpAuth.*
Flag value can be read from the given file when using -logNewSeriesAuthKey=file:///abs/path/to/file or -logNewSeriesAuthKey=file://./relative/path/to/file.
Flag value can be read from the given http/https url when using -logNewSeriesAuthKey=http://host/path or -logNewSeriesAuthKey=https://host/path
-loggerDisableTimestamps
Whether to disable writing timestamps in logs
-loggerErrorsPerSecondLimit int
Per-second limit on the number of ERROR messages. If more than the given number of errors are emitted per second, the remaining errors are suppressed. Zero values disable the rate limit
-loggerFormat string
Format for logs. Possible values: default, json (default "default")
-loggerJSONFields string
Allows renaming fields in JSON formatted logs. Example: "ts:timestamp,msg:message" renames "ts" to "timestamp" and "msg" to "message". Supported fields: ts, level, caller, msg
-loggerLevel string
Minimum level of errors to log. Possible values: INFO, WARN, ERROR, FATAL, PANIC (default "INFO")
-loggerMaxArgLen int
The maximum length of a single logged argument. Longer arguments are replaced with 'arg_start..arg_end', where 'arg_start' and 'arg_end' is prefix and suffix of the arg with the length not exceeding -loggerMaxArgLen / 2 (default 5000)
-loggerOutput string
Output for the logs. Supported values: stderr, stdout (default "stderr")
-loggerTimezone string
Timezone to use for timestamps in logs. Timezone must be a valid IANA Time Zone. For example: America/New_York, Europe/Berlin, Etc/GMT+3 or Local (default "UTC")
-loggerWarnsPerSecondLimit int
Per-second limit on the number of WARN messages. If more than the given number of warns are emitted per second, then the remaining warns are suppressed. Zero values disable the rate limit
-maxConcurrentInserts int
The maximum number of concurrent insert requests. Set higher value when clients send data over slow networks. Default value depends on the number of available CPU cores. It should work fine in most cases since it minimizes resource usage. See also -insert.maxQueueDuration (default 2*cgroup.AvailableCPUs())
-memory.allowedBytes size
Allowed size of system memory VictoriaMetrics caches may occupy. This option overrides -memory.allowedPercent if set to a non-zero value. Too low a value may increase the cache miss rate usually resulting in higher CPU and disk IO usage. Too high a value may evict too much data from the OS page cache resulting in higher disk IO usage. The process may behave unexpectedly if this flag is set too small (e.g., 1 byte).
Supports the following optional suffixes for size values: KB, MB, GB, TB, KiB, MiB, GiB, TiB (default 0)
-memory.allowedPercent float
Allowed percent of system memory VictoriaMetrics caches may occupy. See also -memory.allowedBytes. Too low a value may increase cache miss rate usually resulting in higher CPU and disk IO usage. Too high a value may evict too much data from the OS page cache which will result in higher disk IO usage (default 60)
-metrics.exposeMetadata
Whether to expose TYPE and HELP metadata at the /metrics page, which is exposed at -httpListenAddr . The metadata may be needed when the /metrics page is consumed by systems, which require this information. For example, Managed Prometheus in Google Cloud - https://cloud.google.com/stackdriver/docs/managed-prometheus/troubleshooting#missing-metric-type
-metricsAuthKey value
Auth key for /metrics endpoint. It must be passed via authKey query arg. It overrides -httpAuth.*
Flag value can be read from the given file when using -metricsAuthKey=file:///abs/path/to/file or -metricsAuthKey=file://./relative/path/to/file.
Flag value can be read from the given http/https url when using -metricsAuthKey=http://host/path or -metricsAuthKey=https://host/path
-pprofAuthKey value
Auth key for /debug/pprof/* endpoints. It must be passed via authKey query arg. It overrides -httpAuth.*
Flag value can be read from the given file when using -pprofAuthKey=file:///abs/path/to/file or -pprofAuthKey=file://./relative/path/to/file.
Flag value can be read from the given http/https url when using -pprofAuthKey=http://host/path or -pprofAuthKey=https://host/path
-precisionBits int
The number of precision bits to store per each value. Lower precision bits improves data compression at the cost of precision loss (default 64)
-prevCacheRemovalPercent float
Items in the previous caches are removed when the percent of requests it serves becomes lower than this value. Higher values reduce memory usage at the cost of higher CPU usage. See also -cacheExpireDuration (default 0.1)
-pushmetrics.disableCompression
Whether to disable request body compression when pushing metrics to every -pushmetrics.url
-pushmetrics.extraLabel array
Optional labels to add to metrics pushed to every -pushmetrics.url . For example, -pushmetrics.extraLabel='instance="foo"' adds instance="foo" label to all the metrics pushed to every -pushmetrics.url
Supports an array of values separated by comma or specified via multiple flags.
Each array item can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-pushmetrics.header array
Optional HTTP request header to send to every -pushmetrics.url . For example, -pushmetrics.header='Authorization: Basic foobar' adds 'Authorization: Basic foobar' header to every request to every -pushmetrics.url
Supports an array of values separated by comma or specified via multiple flags.
Each array item can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-pushmetrics.interval duration
Interval for pushing metrics to every -pushmetrics.url (default 10s)
-pushmetrics.url array
Optional URL to push metrics exposed at /metrics page. See https://docs.victoriametrics.com/victoriametrics/single-server-victoriametrics/#push-metrics . By default, metrics exposed at /metrics page aren't pushed to any remote storage
Supports an array of values separated by comma or specified via multiple flags.
Each array item can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-retentionPeriod value
Data with timestamps outside the retentionPeriod is automatically deleted. The minimum retentionPeriod is 24h or 1d. See https://docs.victoriametrics.com/victoriametrics/single-server-victoriametrics/#retention. See also -retentionFilter
The following optional suffixes are supported: s (second), h (hour), d (day), w (week), M (month), y (year). If suffix isn't set, then the duration is counted in months (default 1M)
-retentionTimezoneOffset duration
The offset for performing indexdb rotation. If set to 0, then the indexdb rotation is performed at 4am UTC time per each -retentionPeriod. If set to 2h, then the indexdb rotation is performed at 4am EET time (the timezone with +2h offset)
-rpc.disableCompression
Whether to disable compression of the data sent from vmstorage to vmselect. This reduces CPU usage at the cost of higher network bandwidth usage
-rpc.handshakeTimeout duration
Timeout for RPC handshake between vminsert/vmselect and vmstorage. Increase this value if transient handshake failures occur. See https://docs.victoriametrics.com/victoriametrics/troubleshooting/#cluster-instability section for more details. (default 5s)
-search.maxConcurrentRequests int
The maximum number of concurrent vmselect requests the vmstorage can process at -vmselectAddr. It shouldn't be high, since a single request usually saturates a CPU core, and many concurrently executed requests may require high amounts of memory. See also -search.maxQueueDuration (default 2*cgroup.AvailableCPUs())
-search.maxQueueDuration duration
The maximum time the incoming vmselect request waits for execution when -search.maxConcurrentRequests limit is reached (default 10s)
-search.maxTagKeys int
The maximum number of tag keys returned per search. See also -search.maxLabelsAPISeries and -search.maxLabelsAPIDuration (default 100000)
-search.maxTagValueSuffixesPerSearch int
The maximum number of tag value suffixes returned from /metrics/find (default 100000)
-search.maxTagValues int
The maximum number of tag values returned per search. See also -search.maxLabelsAPISeries and -search.maxLabelsAPIDuration (default 100000)
-search.maxUniqueTimeseries int
The maximum number of unique time series, which can be scanned during every query. This allows protecting against heavy queries, which select unexpectedly high number of series. When set to zero, the limit is automatically calculated based on -search.maxConcurrentRequests (inversely proportional) and memory available to the process (proportional). See also -search.max* command-line flags at vmselect
-secret.flags array
Comma-separated list of flag names with secret values. Values for these flags are hidden in logs and on /metrics page
Supports an array of values separated by comma or specified via multiple flags.
Each array item can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-smallMergeConcurrency int
Deprecated: this flag does nothing
-snapshotAuthKey value
authKey, which must be passed in query string to /snapshot* pages. It overrides -httpAuth.*
Flag value can be read from the given file when using -snapshotAuthKey=file:///abs/path/to/file or -snapshotAuthKey=file://./relative/path/to/file.
Flag value can be read from the given http/https url when using -snapshotAuthKey=http://host/path or -snapshotAuthKey=https://host/path
-snapshotCreateTimeout duration
Deprecated: this flag does nothing
-snapshotsMaxAge value
Automatically delete snapshots older than -snapshotsMaxAge if it is set to non-zero duration. Make sure that backup process has enough time to finish the backup before the corresponding snapshot is automatically deleted
The following optional suffixes are supported: s (second), h (hour), d (day), w (week), M (month), y (year). If suffix isn't set, then the duration is counted in months (default 3d)
-storage.cacheSizeIndexDBDataBlocks size
Overrides max size for indexdb/dataBlocks cache. See https://docs.victoriametrics.com/victoriametrics/single-server-victoriametrics/#cache-tuning
Supports the following optional suffixes for size values: KB, MB, GB, TB, KiB, MiB, GiB, TiB (default 0)
-storage.cacheSizeIndexDBDataBlocksSparse size
Overrides max size for indexdb/dataBlocksSparse cache. See https://docs.victoriametrics.com/victoriametrics/single-server-victoriametrics/#cache-tuning
Supports the following optional suffixes for size values: KB, MB, GB, TB, KiB, MiB, GiB, TiB (default 0)
-storage.cacheSizeIndexDBIndexBlocks size
Overrides max size for indexdb/indexBlocks cache. See https://docs.victoriametrics.com/victoriametrics/single-server-victoriametrics/#cache-tuning
Supports the following optional suffixes for size values: KB, MB, GB, TB, KiB, MiB, GiB, TiB (default 0)
-storage.cacheSizeIndexDBTagFilters size
Overrides max size for indexdb/tagFiltersToMetricIDs cache. See https://docs.victoriametrics.com/victoriametrics/single-server-victoriametrics/#cache-tuning
Supports the following optional suffixes for size values: KB, MB, GB, TB, KiB, MiB, GiB, TiB (default 0)
-storage.cacheSizeMetricNamesStats size
Overrides max size for storage/metricNamesStatsTracker cache. See https://docs.victoriametrics.com/victoriametrics/single-server-victoriametrics/#cache-tuning
Supports the following optional suffixes for size values: KB, MB, GB, TB, KiB, MiB, GiB, TiB (default 0)
-storage.cacheSizeStorageMetricName size
Overrides max size for storage/metricName cache. See https://docs.victoriametrics.com/victoriametrics/single-server-victoriametrics/#cache-tuning
Supports the following optional suffixes for size values: KB, MB, GB, TB, KiB, MiB, GiB, TiB (default 0)
-storage.cacheSizeStorageTSID size
Overrides max size for storage/tsid cache. See https://docs.victoriametrics.com/victoriametrics/single-server-victoriametrics/#cache-tuning
Supports the following optional suffixes for size values: KB, MB, GB, TB, KiB, MiB, GiB, TiB (default 0)
-storage.finalDedupScheduleCheckInterval duration
The interval for checking when final deduplication process should be started.Storage unconditionally adds 25% jitter to the interval value on each check evaluation. Changing the interval to the bigger values may delay downsampling, deduplication for historical data. See also https://docs.victoriametrics.com/victoriametrics/single-server-victoriametrics/#deduplication (default 1h0m0s)
-storage.idbPrefillStart duration
Specifies how early VictoriaMetrics starts pre-filling indexDB records before indexDB rotation. Starting the pre-fill process earlier can help reduce resource usage spikes during rotation. In most cases, this value should not be changed. The maximum allowed value is 23h. (default 1h0m0s)
-storage.maxDailySeries int
The maximum number of unique series can be added to the storage during the last 24 hours. Excess series are logged and dropped. This can be useful for limiting series churn rate. See https://docs.victoriametrics.com/victoriametrics/single-server-victoriametrics/#cardinality-limiter . Setting this flag to '-1' sets limit to maximum possible value (2147483647) which is useful in order to enable series tracking without enforcing limits. See also -storage.maxHourlySeries
-storage.maxHourlySeries int
The maximum number of unique series can be added to the storage during the last hour. Excess series are logged and dropped. This can be useful for limiting series cardinality. See https://docs.victoriametrics.com/victoriametrics/single-server-victoriametrics/#cardinality-limiter . Setting this flag to '-1' sets limit to maximum possible value (2147483647) which is useful in order to enable series tracking without enforcing limits. See also -storage.maxDailySeries
-storage.maxMetadataStorageSize size
Overrides max size for metrics metadata entries in-memory storage. If set to 0 or a negative value, defaults to 1% of allowed memory.
Supports the following optional suffixes for size values: KB, MB, GB, TB, KiB, MiB, GiB, TiB (default 0)
-storage.minFreeDiskSpaceBytes size
The minimum free disk space at -storageDataPath after which the storage stops accepting new data
Supports the following optional suffixes for size values: KB, MB, GB, TB, KiB, MiB, GiB, TiB (default 100000000)
-storage.trackMetricNamesStats
Whether to track ingest and query requests for timeseries metric names. This feature allows to track metric names unused at query requests. See https://docs.victoriametrics.com/victoriametrics/single-server-victoriametrics/#track-ingested-metrics-usage (default true)
-storage.vminsertConnsShutdownDuration duration
The time needed for gradual closing of vminsert connections during graceful shutdown. Bigger duration reduces spikes in CPU, RAM and disk IO load on the remaining vmstorage nodes during rolling restart. Smaller duration reduces the time needed to close all the vminsert connections, thus reducing the time for graceful shutdown. Configured value must always be lower than the graceful shutdown period configured by the orchestration platform (terminationGracePeriodSeconds for Kubernetes). See https://docs.victoriametrics.com/victoriametrics/cluster-victoriametrics/#improving-re-routing-performance-during-restart (default 10s)
-storageDataPath string
Path to storage data (default "vmstorage-data")
-tls array
Whether to enable TLS for incoming HTTP requests at the given -httpListenAddr (aka https). -tlsCertFile and -tlsKeyFile must be set if -tls is set. See also -mtls
Supports array of values separated by comma or specified via multiple flags.
Empty values are set to false.
-tlsCertFile array
Path to file with TLS certificate for the corresponding -httpListenAddr if -tls is set. Prefer ECDSA certs instead of RSA certs as RSA certs are slower. The provided certificate file is automatically re-read every second, so it can be dynamically updated. See also -tlsAutocertHosts
Supports an array of values separated by comma or specified via multiple flags.
Each array item can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-tlsCipherSuites array
Optional list of TLS cipher suites for incoming requests over HTTPS if -tls is set. See the list of supported cipher suites at https://pkg.go.dev/crypto/tls#pkg-constants
Supports an array of values separated by comma or specified via multiple flags.
Each array item can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-tlsKeyFile array
Path to file with TLS key for the corresponding -httpListenAddr if -tls is set. The provided key file is automatically re-read every second, so it can be dynamically updated. See also -tlsAutocertHosts
Supports an array of values separated by comma or specified via multiple flags.
Each array item can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-tlsMinVersion array
Optional minimum TLS version to use for the corresponding -httpListenAddr if -tls is set. Supported values: TLS10, TLS11, TLS12, TLS13
Supports an array of values separated by comma or specified via multiple flags.
Each array item can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-version
Show VictoriaMetrics version
-vminsertAddr string
TCP address to accept connections from vminsert services (default ":8400")
-vmselectAddr string
TCP address to accept connections from vmselect services (default ":8401")
Enterprise vmstorage flags #
These flags are available only in VictoriaMetrics enterprise .
-cluster.tls
Whether to use TLS when accepting connections from vminsert and vmselect. See https://docs.victoriametrics.com/victoriametrics/cluster-victoriametrics/#mtls-protection . This flag is available only in VictoriaMetrics enterprise. See https://docs.victoriametrics.com/victoriametrics/enterprise/
-cluster.tlsCAFile string
Path to TLS CA file to use for verifying certificates provided by vminsert and vmselect if -cluster.tls flag is set. By default system CA is used. See https://docs.victoriametrics.com/victoriametrics/cluster-victoriametrics/#mtls-protection . This flag is available only in VictoriaMetrics enterprise. See https://docs.victoriametrics.com/victoriametrics/enterprise/
-cluster.tlsCertFile string
Path to server-side TLS certificate file to use when accepting connections from vminsert and vmselect if -cluster.tls flag is set. See https://docs.victoriametrics.com/victoriametrics/cluster-victoriametrics/#mtls-protection . This flag is available only in VictoriaMetrics enterprise. See https://docs.victoriametrics.com/victoriametrics/enterprise/
-cluster.tlsCipherSuites array
Optional list of TLS cipher suites used for connections from vminsert and vmselect if -cluster.tls flag is set. See the list of supported cipher suites at https://pkg.go.dev/crypto/tls#pkg-constants . This flag is available only in VictoriaMetrics enterprise. See https://docs.victoriametrics.com/victoriametrics/enterprise/
Supports an array of values separated by comma or specified via multiple flags.
Each array item can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-cluster.tlsInsecureSkipVerify
Whether to skip verification of TLS certificates provided by vminsert and vmselect if -cluster.tls flag is set. Note that disabled TLS certificate verification breaks security. This flag is available only in VictoriaMetrics enterprise. See https://docs.victoriametrics.com/victoriametrics/enterprise/
-cluster.tlsKeyFile string
Path to server-side TLS key file to use when accepting connections from vminsert and vmselect if -cluster.tls flag is set. See https://docs.victoriametrics.com/victoriametrics/cluster-victoriametrics/#mtls-protection . This flag is available only in VictoriaMetrics enterprise. See https://docs.victoriametrics.com/victoriametrics/enterprise/
-downsampling.period array
Comma-separated downsampling periods in the format 'offset:period'. For example, '30d:10m' instructs to leave a single sample per 10 minutes for samples older than 30 days. The 'offset' must be a multiple of 'interval', and when setting multiple downsampling periods for a single filter, those periods must also be multiples of each other. See https://docs.victoriametrics.com/victoriametrics/single-server-victoriametrics/#downsampling for details. This flag is available only in VictoriaMetrics enterprise. See https://docs.victoriametrics.com/victoriametrics/enterprise/
Supports an array of values separated by comma or specified via multiple flags.
Each array item can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-eula
Deprecated, please use -license or -licenseFile flags instead. By specifying this flag, you confirm that you have an enterprise license and accept the ESA https://victoriametrics.com/legal/esa/ . This flag is available only in Enterprise binaries. See https://docs.victoriametrics.com/victoriametrics/enterprise/
-license string
License key for VictoriaMetrics Enterprise. See https://victoriametrics.com/products/enterprise/ . Trial Enterprise license can be obtained from https://victoriametrics.com/products/enterprise/trial/ . This flag is available only in Enterprise binaries. The license key can be also passed via file specified by -licenseFile command-line flag
-license.forceOffline
Whether to enable offline verification for VictoriaMetrics Enterprise license key, which has been passed either via -license or via -licenseFile command-line flag. The issued license key must support offline verification feature. Contact info@victoriametrics.com if you need offline license verification. This flag is available only in Enterprise binaries
-licenseFile string
Path to file with license key for VictoriaMetrics Enterprise. See https://victoriametrics.com/products/enterprise/ . Trial Enterprise license can be obtained from https://victoriametrics.com/products/enterprise/trial/ . This flag is available only in Enterprise binaries. The license key can be also passed inline via -license command-line flag
-licenseFile.reloadInterval duration
Interval for reloading the license file specified via -licenseFile. A non-positive value disables periodic and SIGHUP-triggered reloads of -licenseFile. See https://victoriametrics.com/products/enterprise/ . This flag is available only in Enterprise binaries (default 1h0m0s)
-mtls array
Whether to require valid client certificate for https requests to the corresponding -httpListenAddr . This flag works only if -tls flag is set. See also -mtlsCAFile . This flag is available only in Enterprise binaries. See https://docs.victoriametrics.com/victoriametrics/enterprise/
Supports array of values separated by comma or specified via multiple flags.
Empty values are set to false.
-mtlsCAFile array
Optional path to TLS Root CA for verifying client certificates at the corresponding -httpListenAddr when -mtls is enabled. By default the host system TLS Root CA is used for client certificate verification. This flag is available only in Enterprise binaries. See https://docs.victoriametrics.com/victoriametrics/enterprise/
Supports an array of values separated by comma or specified via multiple flags.
Each array item can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-retentionFilter array
Retention filter in the format 'filter:retention'. For example, '{env="dev"}:3d' configures the retention for time series with env="dev" label to 3 days. See https://docs.victoriametrics.com/victoriametrics/single-server-victoriametrics/#retention-filters for details. This flag is available only in VictoriaMetrics enterprise. See https://docs.victoriametrics.com/victoriametrics/enterprise/
Supports an array of values separated by comma or specified via multiple flags.
Each array item can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
-tlsAutocertCacheDir string
Directory to store TLS certificates issued via Let's Encrypt. Certificates are lost on restarts if this flag isn't set. This flag is available only in Enterprise binaries. See https://docs.victoriametrics.com/victoriametrics/enterprise/
-tlsAutocertEmail string
Contact email for the issued Let's Encrypt TLS certificates. See also -tlsAutocertHosts and -tlsAutocertCacheDir . This flag is available only in Enterprise binaries. See https://docs.victoriametrics.com/victoriametrics/enterprise/
-tlsAutocertHosts array
Optional hostnames for automatic issuing of Let's Encrypt TLS certificates. These hostnames must be reachable at -httpListenAddr . The -httpListenAddr must listen tcp port 443 . The -tlsCertFile and -tlsKeyFile must be unset when -tlsAutocertHosts is used . See also -tlsAutocertEmail and -tlsAutocertCacheDir . This flag is available only in Enterprise binaries. See https://docs.victoriametrics.com/victoriametrics/enterprise/
Supports an array of values separated by comma or specified via multiple flags.
Each array item can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.